
A snapshot of the adoption wave for graphs in the real world and the evolution of their use to support and advance AI – generative or otherwise. Is Knowledge Graph enlightenment here, and what does that mean for AI and RAG?
In the previous edition of the YotG newsletter, the wave of Generative AI hype was probably at its all-time high. Today, while Generative AI is still talked about and trialed, the hype is subsiding. Skepticism is settling in, and for good reason. Reports from the field show that only a handful of deployments are successful.
At its current state, Generative AI can be useful in certain scenarios, but it’s far from being the be-all and end-all that was promised or imagined. The cost and expertise required to evaluate, develop, and deploy Generative AI-powered applications remains substantial.
Promises of breakthroughs remain mostly promises. Adoption, even by the likes of Google and Apple, seems haphazard, with half-baked announcements and demos. At the same time, shortcomings are becoming more evident and understood. This is the typical hype cycle evolution, with Generative AI about to take a plunge in the trough of disillusionment.
Ironically, it is these shortcomings that have been fueling renewed interest in graphs. More specifically, Knowledge Graphs, as part of RAG (Retrieval Augmented Generation). Knowledge graphs are able to deliver benefits deterministically.
Having preceded Generative AI for many years, Knowledge Graphs are entering a more productive phase in terms of their perception and use. Coupled with proper tools and oversight, Generative AI can boost the creation and maintenance of Knowledge Graphs.
Knowledge Graphs as Critical Enablers Reaching the Slope of Enlightenment
Gartner’s Emerging Tech Impact Radar highlights the technologies and trends with the greatest potential to disrupt a broad cross-section of markets. Gartner recently published a list of 30 emerging technologies identified as critical for product leaders to evaluate as part of their competitive strategy.
Knowledge Graphs are at the heart of Critical Enabler technologies. This theme centers on expectations for emerging applications — some of which will enable new use cases and others that will enhance existing experiences — to guide which technologies to evaluate and where to invest.
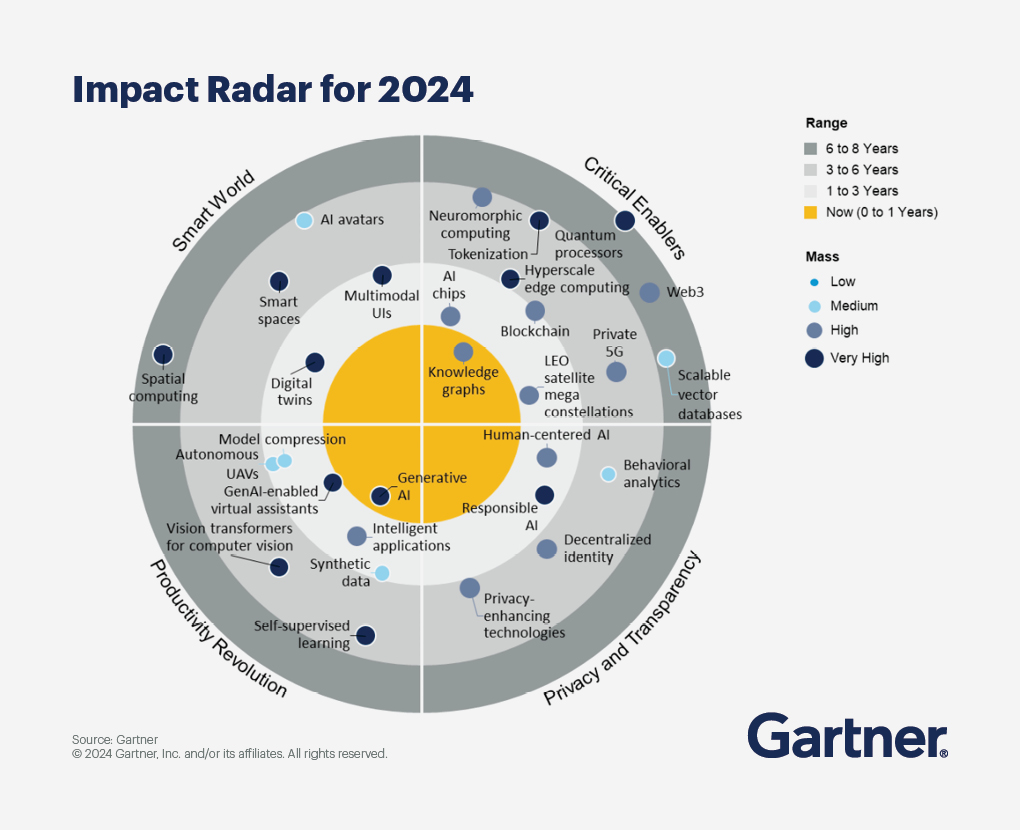
A few days later, at Gartner D&A London, “Adding Semantic Data Integration & Knowledge Graphs” was identified as one of the Top 10 trends in Data Integration and Engineering.
And just a few days before this newsletter issue came out, the Gartner 2024 Hype Cycle for Artificial Intelligence was released. As Research VP of AI at Gartner Svetlana Sicular notes, investment in AI has reached a new high with a focus on generative AI, which, in most cases, has yet to deliver its anticipated business value.
This is why Gen AI is on the downward slope on the Trough of Disillusionment. By contrast, Knowledge Graphs were there in the previous AI Hype Cycle and have now moved to the Slope of Enlightenment.
Graph RAG: Approaches and Evaluation
It was only six months ago when people were still exploring the idea of using knowledge graphs to power RAG. Even though people had used the term Graph RAG before, it was the eponymous publication by a research team in Microsoft that set the tone and made Graph RAG mainstream.
Since the beginning of 2024, there have been 341 arXiv publications on RAG, and counting. Many of these publications refer to Graph RAG, either by introducing new approaches or by evaluating existing ones. And that’s not counting all the non-arXiv literature on the topic. Here is a brief list, and some analysis based on what we know so far.
In “GraphRAG: Design Patterns, Challenges, Recommendations,” Ben Lorica and Prashanth Rao explore options based on their experience both on the drawing board and in the field. In “GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning”, C. Mavromatis and G. Karypis introduce a novel method for combining LLMs with GNNs.
Terence Lucas Yap runs the course “From Conventional RAG to Graph RAG.” Both Neo4j and LangChain have been independently working on Graph RAG until eventually they joined forces as LlamaIndex introduced the Property Graph Index. LinkedIn shared how leveraging a Graph RAG approach enabled cutting customer support resolution time by 28.6%.
Chia Jeng Yang wrote about “The RAG Stack: Featuring Knowledge Graphs”, highlighting that as attention shifts to a ‘RAG stack’, knowledge graphs will be a key unlock for more complex RAG and better performance. Daniel Selman has been researching and building a framework that combines the power of Large Language Models for text parsing and transformation with the precision of structured data queries over Knowledge Graphs for explainable data retrieval.

Graph RAG has not been around for long, but multiple evaluation efforts are already underway. In “Chat with Your Graph” Xiaoxin He et.al introduce G-Retriever, a flexible graph question-answering framework, as well as GraphQA, a benchmark for Graph Question Answering. “A Survey on Retrieval-Augmented Text Generation for Large Language Models” by Huang and Huang presents a framework for evaluating RAG, in which SURGE, a Graph-based method, stands out.
Writer compared Knowledge Graph with other RAG approaches on the basis of accuracy, finding that Knowledge Graph achieved an impressive 86.31% on the RobustQA benchmark, significantly outperforming the competition. Sequeda and Allemang did a follow-up to their previous evaluation, finding that utilizing an ontology reduces the overall error rate to 20%.
In Jay Yu’s micro-benchmark on the performance of GraphRAG, Advanced RAG and ChatGPT-4o, findings were more nuanced. GraphRAG started strong but stumbled due to its knowledge graph dependency. ChatGPT-4o was a general knowledge champ, but it missed a couple of questions. Advanced RAG’s modular architecture clinched the win.
For LinkedIn, RAG + Knowledge Graphs cut customer support resolution time by 28.6%. LinkedIn introduced a novel customer service question-answering method that amalgamates RAG with a knowledge graph. This method constructs a knowledge graph from historical issues for use in retrieval, retaining the intra-issue structure and inter-issue relations.
As Xin Luna Dong shared in her SIGMOD Keynote, “The Journey to a Knowledgeable Assistant with Retrieval-Augmented Generation (RAG)”, there are some clear takeaways. Good metrics are key to quality. Knowledge Graphs increase accuracy and reduce latency, although reducing latency requires relentless optimization. Easy tasks can be distilled to a small LM, and summarization plays a critical role in reducing hallucinations.
For a deeper dive, there’s a book by Tomaž Bratanič and Oskar Hane: Knowledge Graph-Enhanced RAG, currently in Manning Early Access Program (MEAP), set for publication in September 2024.
Connected Data London: Bringing together Leaders and Innovators
Jay Yu has also released a number of chatbots in the last few months, based on the writings of graph influencers such as Kurt Cagle, Mike Dillinger, and Tony Seale, and leveraging LLMs and RAG. There is something else Kurt, Mike, and Tony all have in common too: they will be part of the upcoming Connected Data London 2024 conference.
Connected Data is back in London for what promises to be the biggest, finest, and most diverse in the Connected Data events to date. Join in the City of London on December 11-13 at Venues St. Paul’s for a tour de force in all things Knowledge Graph, Graph Analytics / AI / Data Science / Databases, and Semantic Technology.

Submissions are open across four areas: Presentations, Masterclasses, Workshops, and Unconference sessions. There is also an open call for volunteers and sponsors.
If you are interested in learning more and joining the event or just want to learn from the experts comprising Connected Data London’s Program Committee as they explore this space, mark your calendars.
Connected Data London is organizing a Program Committee Roundtable on July 3, at 3 pm GMT. More details and registration link here.
Subscribe to the Year of the Graph Newsletter
Keeping track of all things Graph Year over Year
Advances in Graph AI and GNN Libraries
There are many advances to report on in the field of Graph AI / Machine Learning / Neural Networks. The best place to start would be to recap progress made in 2023, which is what Michael Galkin and Michael Bronstein do. Their overview in 2 parts covers Theory & Architectures and Applications.
But there is lots of ongoing and future work as well. In terms of research, Azmine Toushik Wasi compiled a comprehensive collection of ~250 graphs and/or GNN papers accepted at the International Conference on Machine Learning 2024.
And it’s not just theory. LiGNN is a large-scale Graph Neural Networks (GNNs) Framework developed and deployed at LinkedIn, which resulted in improvements of 1% in Job application hearing back rate and 2% Ads CTR lift. Google has also been working on a number of directions. Recently, Bryan Perozzi summarized these ideas in “Giving a Voice to Your Graph: Representing Structured Data for LLMs”.

As far as future directions go, Morris et.al argue that the graph machine learning community needs to shift its attention to developing a balanced theory of graph machine learning, focusing on a more thorough understanding of the interplay of expressive power, generalization, and optimization.
Somewhere between past, present and future, Michael Galkin and Michael Bronstein take a stab at defining Graph Foundation Models, keeping track of their progress and outlining open questions. Galkin, Bronstein at.al present a thorough review of this emerging field. See also GFM 2024 – The WebConf Workshop on Graph Foundation Models.
If all this whetted your appetite for applying these ideas, there are some GNN libraries around to help, and they have all been evolving.
- DGL is framework agnostic, efficient and scalable, and has a diverse ecosystem. Recently, version 2.1 was released featuring GPU acceleration for GNN data pipelines.
- MLX-graphs is a library for GNNs built upon Apple’s MLX, offering fast GNN training and inference, scalability and multi-device support.
- PyG v2.5 was released featuring distributed GNN training, graph tensor representation, RecSys support, PyTorch 2.2 and native compilation support.
Last but not least in the chain of bringing Graph AI to the real world, NVIDIA introduced WholeGraph Storage, optimizing memory and retrieval for Graph Neural Networks, and extended its focus to its role as both a storage library and a facilitator of GNN tasks.
Graph Database Market Growth and the GQL Standard
Gartner analysts Adam Ronthal and Robin Schumacher, Ph.D. recently published their market analysis, including an infographic stack ranking of revenue in the DBMS market. This is a valuable addition to existing market analysis, as it covers what other sources typically lack: market share approximation.
The analysis includes both pure-play graph database vendors (Neo4j and TigerGraph), as well as vendors whose offering also includes a graph (AWS, Microsoft, Oracle, DataStax, AeroSpike, and Redis – although its graph module was discontinued in 2023).
The dynamics at the top, middle, and bottom of the stack are pretty much self-explanatory, and Neo4j and TigerGraph are on the rise. A propos, Neo4j keeps on executing its partnership strategy, having just solidified the partnerships with Microsoft and Snowflake.
It would also be interesting to explore how much Graph contributes to the growth of other vendors, but as Ronthal notes, the granularity of the data does not enable this.

In other Graph DB news, Aerospike announced $109M in growth capital from Sumeru Equity Partners. As per the press release, the capital injection reflects the company’s strong business momentum and rising AI demand for vector and graph databases. Note the emphasis on Graph, coming from a vendor that is a recent entry in this market.
Another new entry in the Graph DB market is Falkor DB. In a way, Falkor picks up from where Redis left off, as it’s developed as a Redis module. Falkor is open source and supports distribution and the openCypher query language. It’s focused on performance and scalability, and targets RAG use cases.
Speaking of query languages, however, perhaps the biggest Graph DB news in a while is the official release of GQL. GQL (Graph Query Language) is now an ISO standard just like SQL. It’s also the first new ISO database language since 1987 — when the first version of SQL was released. This will help interoperability and adoption for graph technologies.
For people who have been involved in this effort that started in 2019, this may be the culmination of a long journey. Now it’s up to vendors to implement GQL. Neo4j has announced a path from openCypher to GQL, and TigerGraph also hailed GQL. It’s still early days, but people are already exploring and creating open source tools for GQL.
Knowledge Graph Research, Use Cases and Data Models
Wrapping up this issue of the newsletter with more Knowledge Graph research and use cases. In “RAG, Context and Knowledge Graphs” Kurt Cagle elaborates on the tug of war between machine learning and symbolic AI, manifested in the context vs. RAG debate. As he notes, both approaches have their strengths as well as their issues.
In “How to Implement Knowledge Graphs and Large Language Models (LLMs) Together at the Enterprise Level,” Steve Hedden surveys current methods of integration. At the same time, organizations such as Amazon, DoorDash and the Nobel Prize Outreach share how they did it.
There are also many approaches for creating Knowledge Graphs assisted by LLMs. Graph Maker, Docs2KG and PyGraft are just a couple of these. This almost begs the question – can Knowledge Graph creation be entirely automated? Are we looking at a future in which the job of Knowledge Graph builders, aka ontologists, will be obsolete?
The answer, as is most likely for most other jobs too, is probably no. As Kurt Cagle elaborates in “The Role of the Ontologist in the Age of LLMs”, an ontology, when you get right down to it, can be thought of as the components of a language.
LLMs can mimic and recombine language, sometimes in a seemingly brilliant and creative way, but they don’t really understand either language, or the domain it’s used to describe. They may be able to produce a usable model, but the knowledge and effort needed to verify, debug and complement it are not negligible.
As Cagle also notes, some ontologies may have thousands of classes and hundreds of thousands of relationships. Others, however, are tiny, with perhaps a dozen classes and relationships, usually handling very specialized tasks.
Cagle mentions SKOS, RDFS, and SHACL as examples of small ontologies handling specialized tasks. What they all handle is ontology, or more broadly, model creation itself. The art of creating ontological models for knowledge graphs, as Mike Dillinger points out, often starts with taxonomies.

Still, taxonomies are the structural core of ontologies and knowledge graphs as well as the foundation of all of our efforts to organize explicit knowledge. Dillinger believes that we can do better than today’s taxonomies – what he calls Taxonomy 2.0. He shares his take on building knowledge graphs in “Knowledge Graphs and Layers of Value”, a 3-part series.
Building these semantic models may be slow, as Ahren Lehnert notes in “The Taxonomy Tortoise and the ML Hare”. But it enables fast-moving machine learning models and LLMs to be grounded in organizational truths, allowing for expansion, augmentation, and question-answering at a much faster pace but backed with foundational truths.
All of the above point to semantic knowledge graphs and RDF. When it comes to choosing the right type of graph model, the decision typically boils down to two major contenders: Resource Description Framework (RDF) and Labelled Property Graphs (LPG).
Each has its own unique strengths, use cases, and challenges. In this episode of the GraphGeeks podcast hosted by Amy Hodler, Jesús Barrasa and Dave Bechberger discuss how these approaches are different, how they are similar, and how and when to use each.
GQL, mentioned earlier, applies to LPG. But it could also be used as a means to bring the two worlds closer together. This is what Ora Lassila explores in his “Schema language for both RDF and LPGs” presentation, also building on his previous work with RDF and reification. Semih Salihoğlu and Ivo Velitchkov both praise RDF, listing pros and cons and seeing it as an enabler for liberating cohesion, respectively.
Subscribe to the Year of the Graph Newsletter
Keeping track of all things Graph Year over Year