
Authors:
(1) Rui Duan University of South Florida Tampa, USA (email: ruiduan@usf.edu);
(2) Zhe Qu Central South University Changsha, China (email: zhe_qu@csu.edu.cn);
(3) Leah Ding American University Washington, DC, USA (email: ding@american.edu);
(4) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu);
(5) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu).
Table of Links
Parrot Training: Feasibility and Evaluation
PT-AE Generation: A Joint Transferability and Perception Perspective
Optimized Black-Box PT-AE Attacks
VI. EXPERIMENTAL EVALUATIONS
In this section, we measure the impacts of our PT-AE attack in real-world settings. We first describe our setups and then present and discuss experimental results.
A. Experimental Settings
The settings of the PT-AE attack: We select 3 CNN and 3 TDNN models to build N = 6 PT models with different parameters for ensembling in (5). Each PT model has the same one-sentence knowledge (8-second speech) of the target speaker, which is selected from the LibriSpeech [87] or VoxCeleb1 [83] datasets. We randomly choose 6-16 speakers from the VCTK dataset as other speakers to build each PT model. We choose K = 50 carriers from the 200 environmental sound carriers in [47] to form the candidate set for the attacker and can shift the pitch of a sound up/down by up to 25 semitones. The total energy threshold ϵ is set to be 0.08.

Target speaker recognition systems: We aim to evaluate the attacks against two major types of speaker recognition systems: i) digital-line evaluations: we directly forward AEs to the open-source systems in the digital audio file format (16- bit PCM WAV) to evaluate the attack impact. ii) over-the-air evaluations: we perform over-the-air attack injections to the real-world smart devices.
Evaluation metrics: (i) Attack effectiveness: we use attack success rate (ASR) to evaluate the percentage of AEs that can be successfully recognized as the target speaker in a speaker recognition system. (ii) Perception quality: we evaluate the perception quality of an AE via the metric of SRS.
B. Evaluations of Digital-line Attacks
Digital-line setups: We consider choosing 4 different target models from statistical-based, i.e., GMM-UBM and ivector-PLDA [5], and DNN-based, i.e., DeepSpeaker [68] and ECAPA-TDNN [41] models. To increase the diversity of target models, we aim to choose 3 males and 3 females from LibriSpeech and VoxCeleb1. For each gender, we randomly select 1 or 2 speakers from LibriSpeech then randomly select the other(s) from VoxCeleb1. We choose around 15-second speech from each speaker to enroll with each speaker recognition model. The performance of each target speaker recognition model is shown in Appendix C.
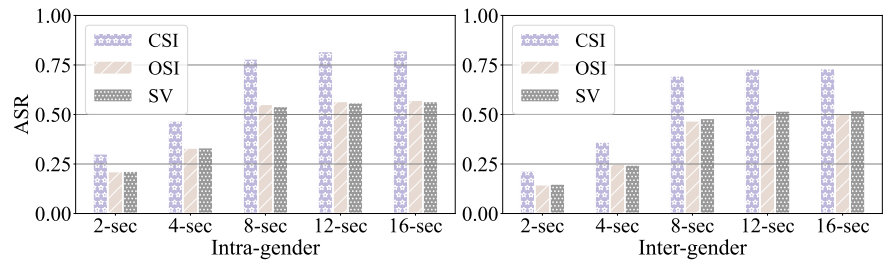
Results of digital-line attacks: In digital-line evaluations, we measure the performance of each attack strategy by generating 240 AEs (40 AEs for each target speaker) against each target speaker recognition model. We separate the results by the intragender (i.e., the original speaker whose speech is used for AE generation is the same-gender as the target speaker) and inter-gender scenario (the original and target speakers are not the same-gender, indicating more distinct speech features). We also evaluate the attacks against three tasks: CSI, OSI, and SV.
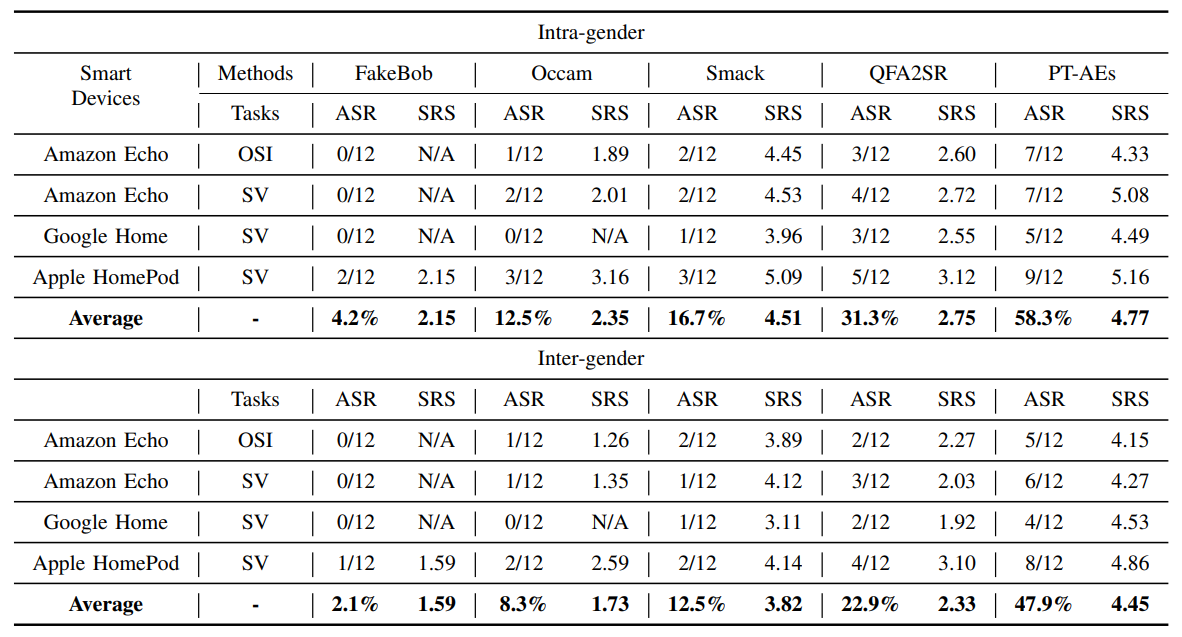
Table V shows the ASRs and SRSs of AEs generated by our PT-AE attack strategy, compared with other attack strategies, against CSI, OSI, and SV tasks. It is noted from Table V that in the intra-gender scenario, the PT-AE attack and QFA2SR (e.g., 60.2% for PT-AE attack and 40.0% for QFA2SR) can achieve higher averaged ASRs (over all three tasks) than other attacks (e.g., 11.3% for FakeBob, 19.2% for Occam, and 29.9% Smack). At the same time, the results of averaged SRS reveal that the perception quality of the PT-AE attack (e.g., 4.1 for PT-AE attack and 3.1 for Smack) is better than other attacks (e.g., 2.3 for QFA2SR, 2.1 for Occam, and 2.9 for FakeBob). In addition, it can be observed that in the inter-gender scenario, the ASRs and SRSs become generally worse. For example, the ASR of FakeBob changes from 11.3% to 6.9% from the intra-gender to inter-gender scenario. But we can see that our PT-AE attack is still effective in terms of both average ASR (e.g., 54.6% for PT-AE attack vs 29.7% for QFA2SR) and average SRS (e.g., 3.9 for PT-AE attack vs 3.2 for Smack). The results in Table V demonstrate that the PT-AE attack is the most effective in achieving both black-box attack success and perceptual quality.
C. Impacts of Attack Knowledge Levels
1) Impacts of speech length on attack effectiveness: By default, we build each PT model in our attack using an 8-second speech sample from the target speaker. We are interested in how the attacker’s knowledge affects the PT-AE effectiveness. We assume that the attacker knows the target speaker’s speech from 2 to 16 seconds and constructs different PT models based on this varying knowledge to create PT-AEs.
Results analysis: Fig. 8 shows the ASRs of PT-AEs under different knowledge levels. We can see that more knowledge can increase the attacker’s ASR. When the attack knowledge starts to increase from 2 to 8 seconds, the ASR increases substantially (e.g., 21.3% to 55.2% against OSI in the intragender scenario). When it continues to increase to 16 seconds, the ASR exhibits a slight increase. One potential explanation is that the ASR can be influenced by the differences in the architecture and training data between the surrogate and target models. Meanwhile, the one-shot VC method could also reach a performance bottleneck in converting parrot samples using even longer speech. In addition, increasing the speech length
does not always indicate the increase of phoneme diversity, which can be also important in speech evaluation [81], [22]. Existing studies [75], [104] highlighted that phonemes represent an important feature of the voiceprint to train the VC model. Thus, we aim to explore further how phoneme diversity (in addition to sentence length) can influence the ASR.
2) Impacts of phoneme diversity: Since there is no clear, uniform definition for phoneme diversity in previous VC studies [75], [104], we define it as the number of unique phonemes present in a given speech segment. It is worth noting that while some phonemes might appear multiple times in the segment, each is counted only once towards phoneme diversity. This approach is taken because, from an attacker’s perspective, unique phonemes are more valuable than repeated ones. While unique phonemes contribute distinct voiceprint features to a VC model, repeated phonemes, can be easily replicated and offer less distinctiveness [75].
To evaluate the impact of phoneme diversity on ASR, we choose speech samples of target speakers that have different phoneme diversities but are of the same length (measured by seconds). From our observations in existing datasets (e.g., LibriSpeech), a shorter speech sample can exhibit a higher phoneme diversity than a longer speech sample. This allows us to select speech samples with significantly different levels of phoneme diversity under the same speech length constraint.
We establish low and high phoneme diversity groups in speech segments of the same length to better understand the impact of phoneme diversity on attack effectiveness. In particular, for each level of speech length (e.g., 8-second) in a dataset, we first rank the speech sample of each target speaker by phoneme diversity, then group the top half of all samples (with high values of phoneme diversity) as the high phoneme diversity group and the bottom half as the low diversity group. In this way, the low phoneme diversity group has fewer distinctive phonemes than the high group, offering enough difference regarding attack knowledge for comparison.
We construct our attack knowledge speech set using the speech samples of 3 male and 3 female speakers from LibriSpeech and VoxCeleb1, consistent with the digital-line setups detailed in Section VI-B. Our goal is to capture various phoneme diversities under different speech lengths. Table VI shows the average phoneme diversity and the total number of phonemes of speech samples in the low and high diversity groups under the same level of speech length (2 to 16 seconds). Table VI demonstrates that the phoneme diversity increases as the speech length increases. Moreover, we find that the
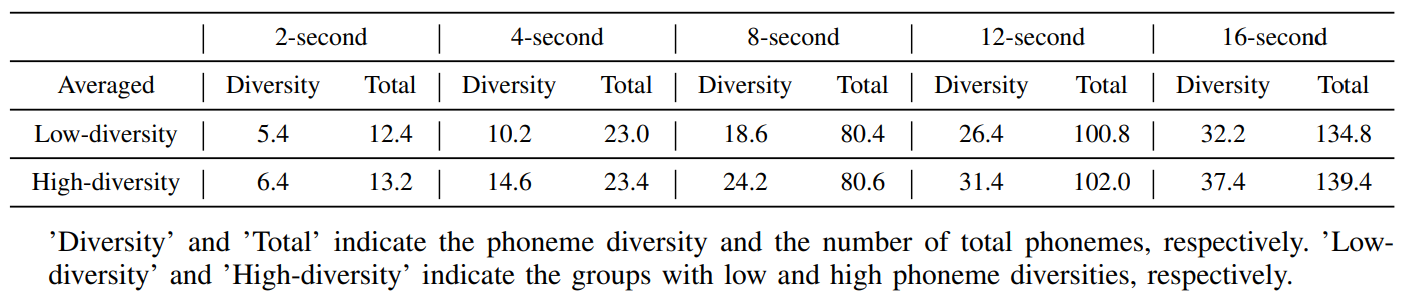
phoneme diversity can vary evidently even when the number of total phonemes is similar. For the 8-second category, the low phoneme diversity group has an average diversity of 18.6, while the high diversity group has 24.2. Despite this difference, they have a similar total number of phonemes (80.4 vs 80.6).
Then, under each level of speech length (2, 4, 8, 12, 16 seconds) for each target speaker (3 male and 3 female speakers), we use speech samples from the low and high phoneme diversity groups for parrot training and generate 90 PT-AEs from each group. This resulted in a total of 5,400 PT-AEs for the phoneme diversity evaluation.
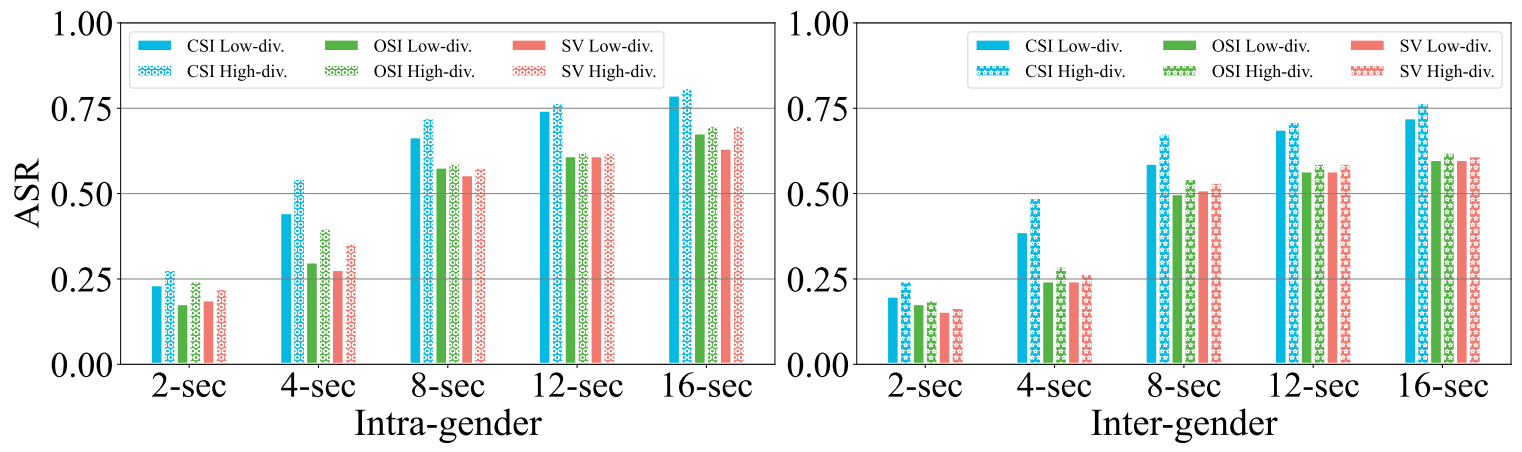
Results analysis: Fig. 9 shows the ASRs of PT-AEs generated from low and high diversity groups against CSI, OSI, and SV tasks. It can be seen from the figure that the high diversity group-based PT-AEs have a higher ASR than the low diversity ones in both intra-gender and inter-gender scenarios. For example, the inter-gender ASRs are 47.70% (low-diversity) vs 55.56% (high-diversity). The largest difference in ASR is observed in the 4-second case in the CSI task for the intragender scenario, with a maximum difference of 10.0%. The results show that using speech samples with high phoneme diversity for parrot training can indeed improve the attack effectiveness of PT-AEs.
In addition, we calculate via Pearson’s coefficients [54] the correlation of the ASR with each of the methods to measure the attack knowledge level, including measuring the speech length, counting the total number of phonemes, and using the phoneme diversity. We find that phoneme diversity achieves the highest Pearson’s coefficient of 0.9692 in comparison with using speech length (0.9341) and counting the total number of phonemes (0.9574). As a result, the phoneme diversity for measuring the attack knowledge is the most related to the attack effectiveness, while using the speech length or the total number of phonemes can still be considered adequate as they both have high Pearson’s coefficients.
D. Evaluations of Over-the-air Attacks
Next, we focus on attacking the smart devices in the overthe-air scenario. We consider three popular smart devices: Amazon Echo Plus [8], Google Home Mini[11], and Apple HomePod (Siri) [3]. For speaker enrollment, we use 3 male and 3 female speakers from Google’s text-to-speech platform to generate the enrollment speech for each device. We only use an 8-second speech from each target speaker to build our PT models. We consider OSI and SV tasks on Amazon Echo, and the SV task on Apple HomePod and Google Home. Similarly, we evaluate the different attacks in both intra-gender and intergender scenarios. For each attack strategy, we generate and play 24 AEs using a JBL Clip3 speaker to each smart device with a distance of 0.5 meters.
Results analysis: Table VII compares different attack methods against the smart devices under various tasks. We can see that our PT-AE attack can achieve average ASRs of 58.3% (intra-gender) and 47.9% (inter-gender) and at the same time the average SRSs of 4.77 (intra-gender) and 4.45 (intergender). By contrast, QFA2SR has the second-best ASRs of 31.3% (intra-gender) and 22.92% (inter-gender); however, it has a substantially lower perception quality compared with the PT-AE attack and Smack, e.g., 2.75 (QFA2SR) vs 4.51 (Smack) vs 4.77 (PT-AE attack) in the intra-gender scenario. We also find that FakeBob and Occam appear to be ineffective with over-the-air injection as zero ASR is observed against Amazon Echo and Google Home. Overall, the over-the-air results demonstrate that the PT-AEs generated by the PT-AE attack can achieve a high ASR with good perceptual quality. Additionally, we also evaluated the robustness of PT-AEs over distance, the results can be found in Table X in Appendix D.
E. Contribution of Each Component to ASR
As the PT-AE generation involves three major design components, including parrot training, choosing carriers, and ensemble learning, to enhance the overall transferability, we
propose to evaluate the contribution of each individual component to the ASR. Our methodology is similar to the One-at-a-time (OAT) strategy in [44]. Specifically, we remove and replace each design component with an alternative, baseline approach (as a baseline attack), while maintaining the other settings the same in generating PT-AEs, and then compare the resultant ASR with the ASR of no-removing PT-AEs (i.e., the PT-AEs generated without removing/replacing any design component). Through this method, we can determine how each component contributes to the overall attack effectiveness.
We use the same over-the-air attack setup as described in Section VI-D. For each baseline attack, we craft 96 AEs for both intra and inter-gender scenarios. These AEs are played on each smart device by the same speaker at the same distance. We present the experimental setup and results regarding evaluating the contribution of each design component as follows.
1) Parrot training: Rather than training the surrogate models with parrot speech, we directly use the target speaker’s one- sentence (8-second) speech for enrollment with the surrogate models. These surrogate models, which we refer to as non-parrot-training (non-PT) models, are trained on the datasets that exclude the target speakers’ speech samples.
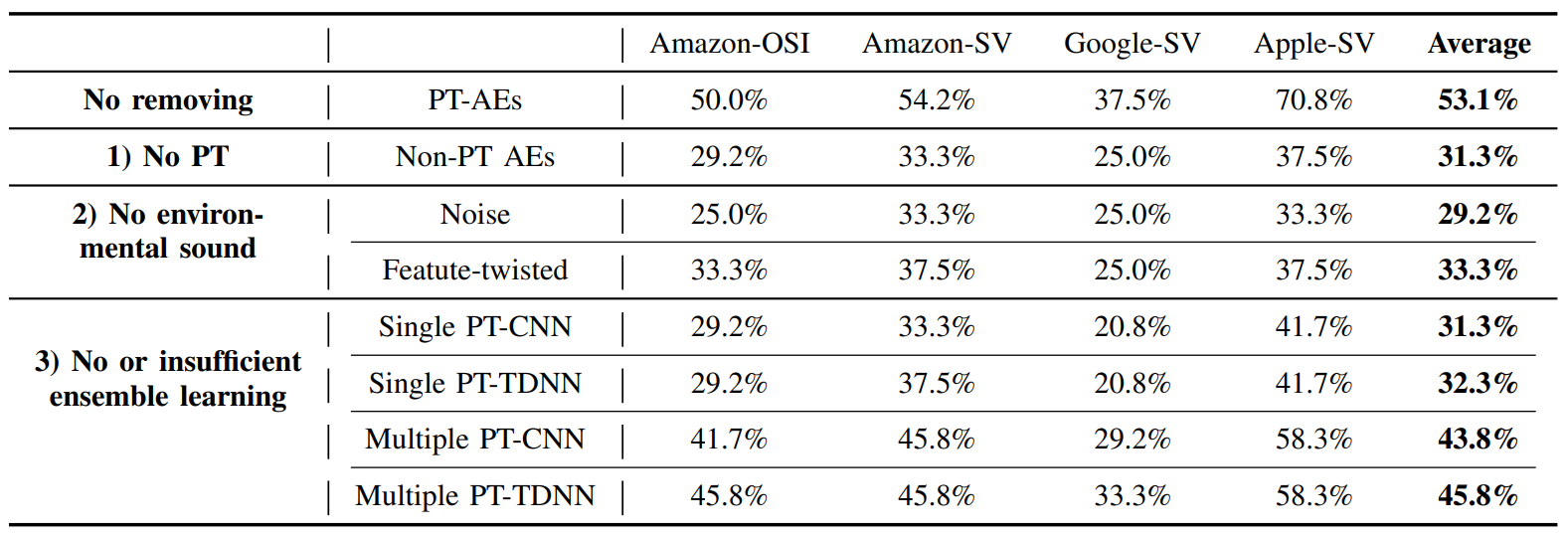
Results: As shown in Table VIII (the “No PT” row), we observe a significant ASR difference between non-PT-based AEs and no-removing PT-AEs. For example, in the AmazonSV task, PT-AEs achieve an ASR of 54.2%, which is 20.9% higher than the 33.3% ASR of non-PT AEs. Overall, the average ASR for PT-AEs is 21.8% higher than that of nonPT AEs. This substantial performance gap is primarily filled by adopting parrot training.
2) Environmental sound carrier: To understand the contribution of the feature-twisted environment sound carrier, we use two baseline attacks related to noise and feature-twisted carriers. i) Noise carriers, we employ the PGD attack to generate the AEs based on the PT models through ensemble learning, setting ϵ = 0.05 to control the L∞ norm. ii) Feature twisted carriers, as discussed in Section V-A, we shift the pitch of the original speech up or down by up to 25 semitones to create a pitch-twisted set. We use this set to solve the problem in (5) via finding the optimal weights for the twisted-pitch carriers, with a total energy threshold of ϵ = 0.08.
Results: Table VIII (the “no environmental sound” rows) indicates that environmental-sound-based PT-AEs hold a distinct advantage over other carriers in terms of attack effectiveness. We note that when we exclude the feature-twisted environmental sound carriers and rely solely on either the noise or feature twisted carriers, the average ASR drops by 23.9% (vs. noise carrier) and 19.8% (vs. feature-twisted carrier). These findings
show that utilizing feature-twisted environmental sounds can significantly enhance the attack effectiveness.
3) Ensemble learning: We note that our ensemble-based model in (5) combines multiple CNN and TDNN models. To evaluate the contribution of ensemble learning, we design two sets of experiments. First, we replace the ensemble-based model in (5) with just a single PT-CNN or PT-TDNN model to compare the ASRs. Second, we replace (5) with an ensemble-based model, which only consists of multiple (in particular 6 in experiments) surrogate models under the same CNN or TDNN architecture (i.e., no ensembling across different architectures).
Results: We can observe in Table VIII (the “no or insufficient ensemble learning” rows) that the single PT-CNN and PTTDNN models only have average ASRs of 31.3% and 32.3%, respectively. If we do adopt ensemble learning but combine surrogate models under the same architecture, the average ASRs can be improved to 43.8% and 45.8% under multiple PT-CNN and PT-TDNN models, respectively. By contrast, noremoving PT-AEs achieve the highest average ASR of 53.1%.
In summary, the three key design components for PT-AEs, i.e., parrot training, feature-twisted environmental sounds, and ensemble learning, improve the average ASR by 21.8%, 21.9%, and 21.3%, respectively, when compared with their individual baseline replacements. As a result, they are all important towards the black-box attack and have approximately equal contribution to the overall ASR.
F. Human Study of AEs Generated in Experiments
We have used the metric of SRS based on regression prediction built upon the human study in Section IV-B to assess that the PT-AEs have better perceptual quality than AEs generated by other attack methods in experimental evaluations. We now conduct a new round of human study to see whether PT-AEs generated in the experiments are indeed rated better than other AEs by human participants. Specifically, we have recruited additional 45 student volunteers (22 females and 23 males), with ages ranging from 18 to 35. They are all first-time participants and have no knowledge of the previous human study in Section IV-B. Following the same procedure, we ask each volunteer to rate each pair of original and PT-AE samples.
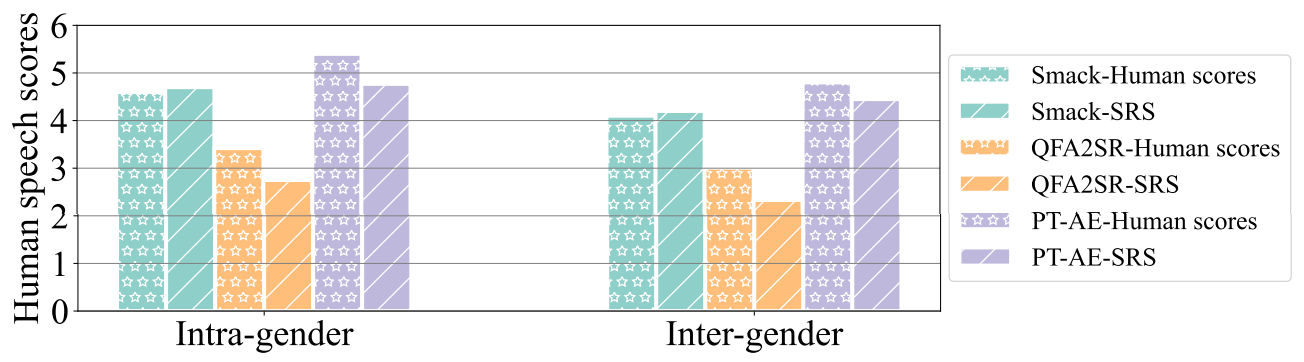
Fig. 10 shows the average human speech scores of Smack, QFA2SR, and our attack. We can see that PT-AEs generated by our attack are rated higher than Smack and QFA2SR. In the intra-gender scenario, the average human score of our attack is 5.39, which is higher than Smack (4.61) and QFA2SR (3.62). The score for each method drops slightly in the inter-gender scenario. The results align with the SRS findings in Table VII. We also find SRS scores are close to human scores. In the intergender scenario, SRS predicts our PT-AEs perceptual quality as 4.45, close to the human average of 4.8. The results of Fig. 10 further validates that the PT-AEs have better perceptual quality than AEs generated by other methods.
G. Discussions
Ethical concerns and responsible disclosure: Our smart device experiments did not involve any person’s private information. All the experiments were set up in our local lab. We have reported our findings to manufacturers (Amazon, Apple, and Google). All manufacturers thanked our research and disclosure efforts aimed at safeguarding their services. Google responded promptly to our investigations, confirming that there is a voice mismatch issue and closed the case as they stated that the attack requires the addition of a malicious node. We are still in communication with Amazon and Apple.
We also discuss potential defense strategies against PTAEs. Due to the page limit, we have presented the defense discussion in Appendix E.
This paper is available on arxiv under CC0 1.0 DEED license.