
In distributed systems and microservices, message brokers are essential. They enable asynchronous communication, decouple services, and enhance reliability and scalability. Modern architecture heavily depends on message brokers, making them a key component in many design patterns.
Kafka and RabbitMQ are two of the most popular message brokers. They are known for being reliable, efficient, and adaptable, with excellent documentation, support, and communities.
RabbitMQ is a free and open-source solution, dual-licensed under the Apache License 2.0 and Mozilla Public License 2. It allows you to use and modify it as needed. It functions as a pure message broker, supporting multiple protocols and offering additional features.
Kafka, also open-source under the Apache 2.0 license, is more than just a message broker; it's a distributed event streaming platform. It provides advanced features, including Kafka Streams.
When comparing RabbitMQ and Kafka, there's no "better" solution; it's about finding the best fit for your architecture and objectives.
This article will walk you through key features and characteristics, comparing the two directly. It aims to provide a comprehensive understanding of the differences between Kafka and RabbitMQ, assisting you in making an informed choice based on your specific problem and requirements.
Protocols support
RabbitMQ supports various protocols such as:
- MQTT (MQ Telemetry Transport) is a lightweight protocol for limited bandwidth and high-latency networks, such as those in the Internet of Things (IoT). Initially created for monitoring oil pipelines, it is now widely used as a pub-sub messaging protocol.
- STOMP (Simple Text Oriented Messaging Protocol) is a simple, lightweight text-based protocol for messaging integrations, well-suited for use over WebSocket and the Web.
- AMQP (Advanced Message Queuing Protocol) is the primary protocol for RabbitMQ, detailing various routing options. Although RabbitMQ can support other protocols through plugins, AMQP is its core protocol.
On the other hand, Kafka uses its binary TCP-based protocol optimized for high throughput and relies on a "message set" abstraction. This abstraction allows network requests to group messages together, reducing the overhead of network round-trips by sending batches instead of individual messages. Kafka's custom protocol enables flexibility in development and optimization for high-load scenarios.
However, the custom protocol also has drawbacks. It isolates Kafka from other message brokers, leading to a lack of interoperability. Unlike RabbitMQ, which is compatible with any AMQP client, Kafka requires using Kafka clients. Nonetheless, due to Kafka's popularity and community efforts, Kafka clients are available for many programming languages.
Routing
The routing approach in RabbitMQ and Kafka differs significantly.
RabbitMQ Routing
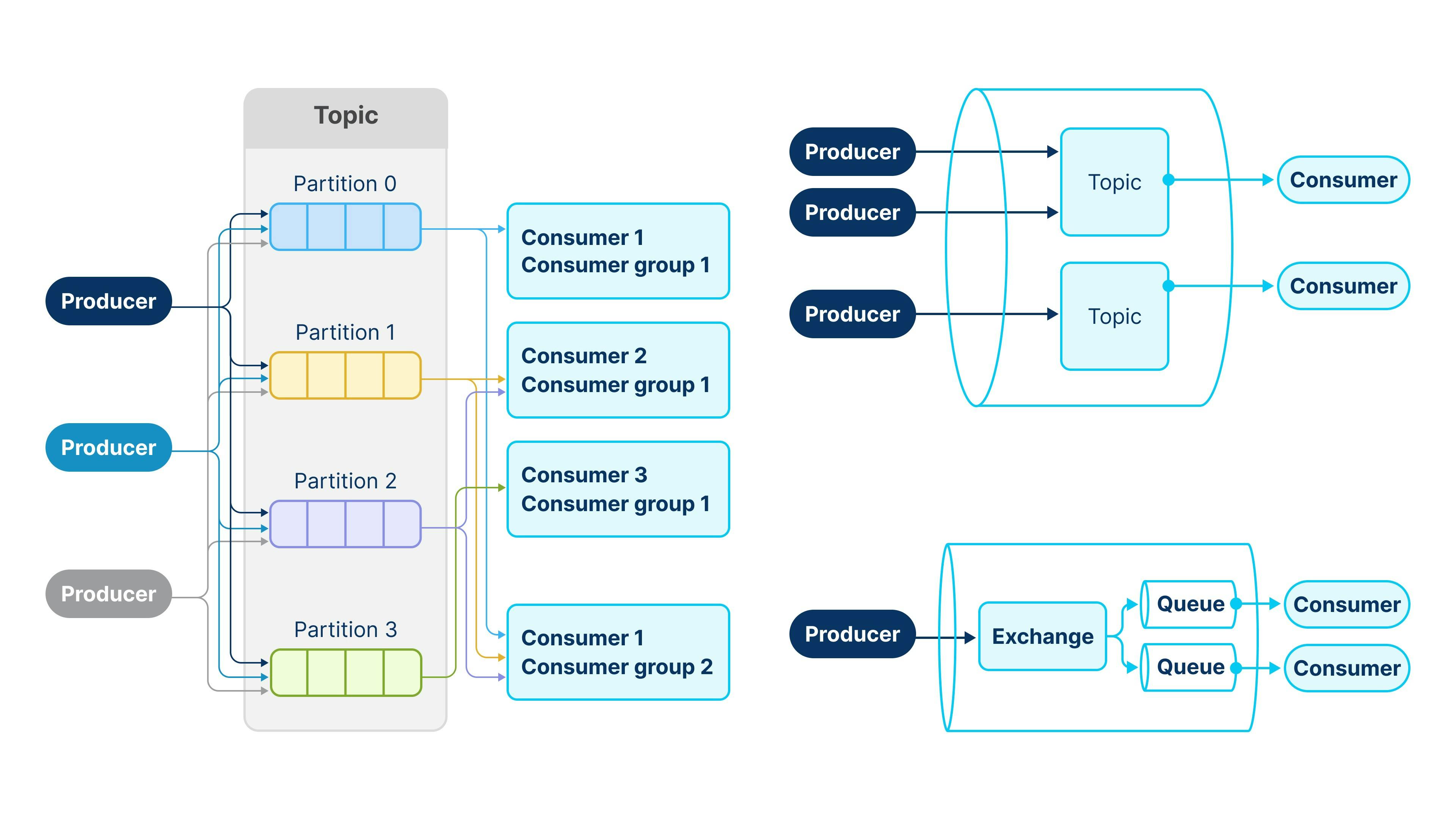
The main components of RabbitMQ routing:
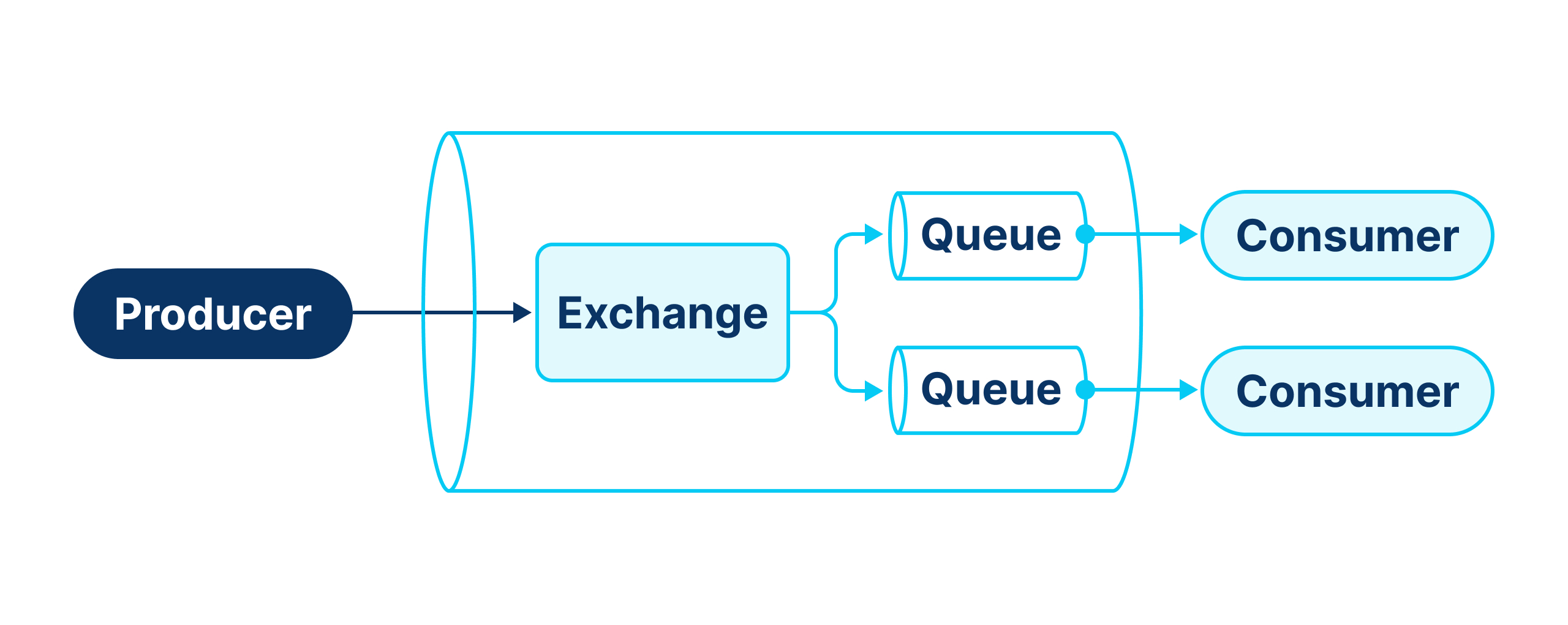
- Producer. An application that generates and sends messages to RabbitMQ.
- Exchange. Receives messages from the Producer and routes them to one or more queues.
- Queue. Stores messages.
- Consumer. An application that subscribes to a queue and receives messages from it. RabbitMQ pushes messages to the Consumer, and each Consumer gets messages from only one queue.
Before delving into Exchanges, we should clarify two more concepts:
- Binding. A rule describes how to route messages from the Exchange to a Queue. Typically, a Consumer binds a Queue to a specific Exchange when creating it.
- Routing Key. In RabbitMQ, the Producer cannot directly specify the Queue for a message. The Exchange routes messages based on the Routing Key provided by the Producer, which consists of one or more strings separated by dots.
There are four types of Exchange:
- Default. Routes messages directly to a Queue using the Queue name from the Routing Key.
- Fanout. Broadcasts messages to all bound Queues, ignoring the Routing Key.
- Direct. Routes messages to Queues based on exact matches between the Routing Key and the binding key provided by the Queue.
- Topic. Allows complex routing rules based on pattern matching of the Routing Key, supporting wildcard characters:
-
*(star) matches exactly one word.
-
#(hash) matches zero or more words.
For example, a queue bound with the routing key "apple.*.banana" would receive messages with keys like "apple.orange.banana" or "apple.strawberry.banana". A queue bound with #.banana would receive messages with keys like "apple.banana" or "apple.orange.banana".
Kafka
Kafka's routing is simpler. The main components are:
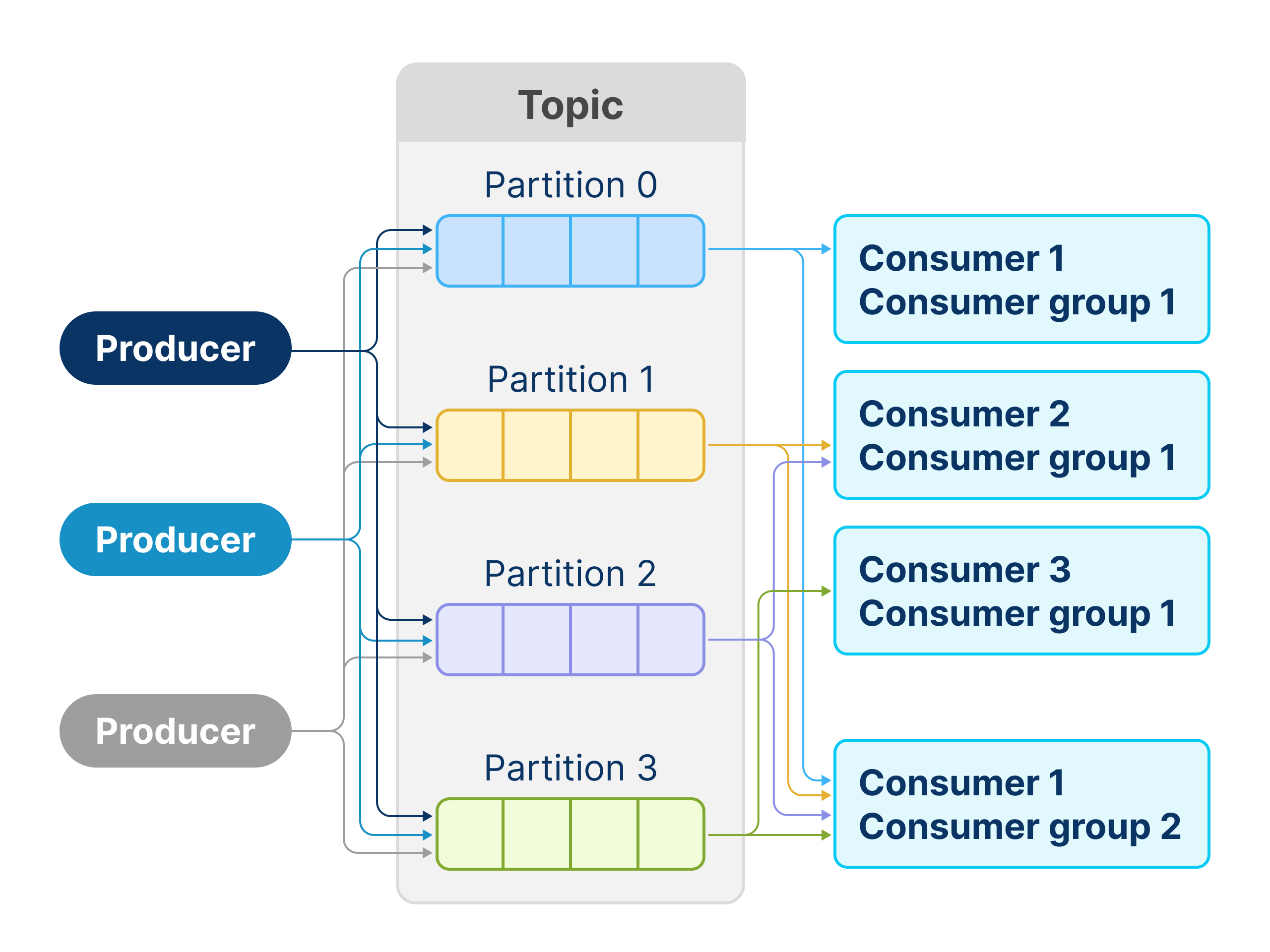
- Producer. Similar to RabbitMQ, it sends messages to a Topic.
- Topic. Stores messages. Producers specify the Topic to which they send messages.
- Partitions. Each Topic divides into partitions, representing the physical storage of messages. Producers can specify a key to route messages, ensuring all messages with the same key belong to the same partition.
- Consumer. Unlike RabbitMQ Consumers, Kafka Consumers pull messages from Topics. They can read messages from only one Topic at a time.
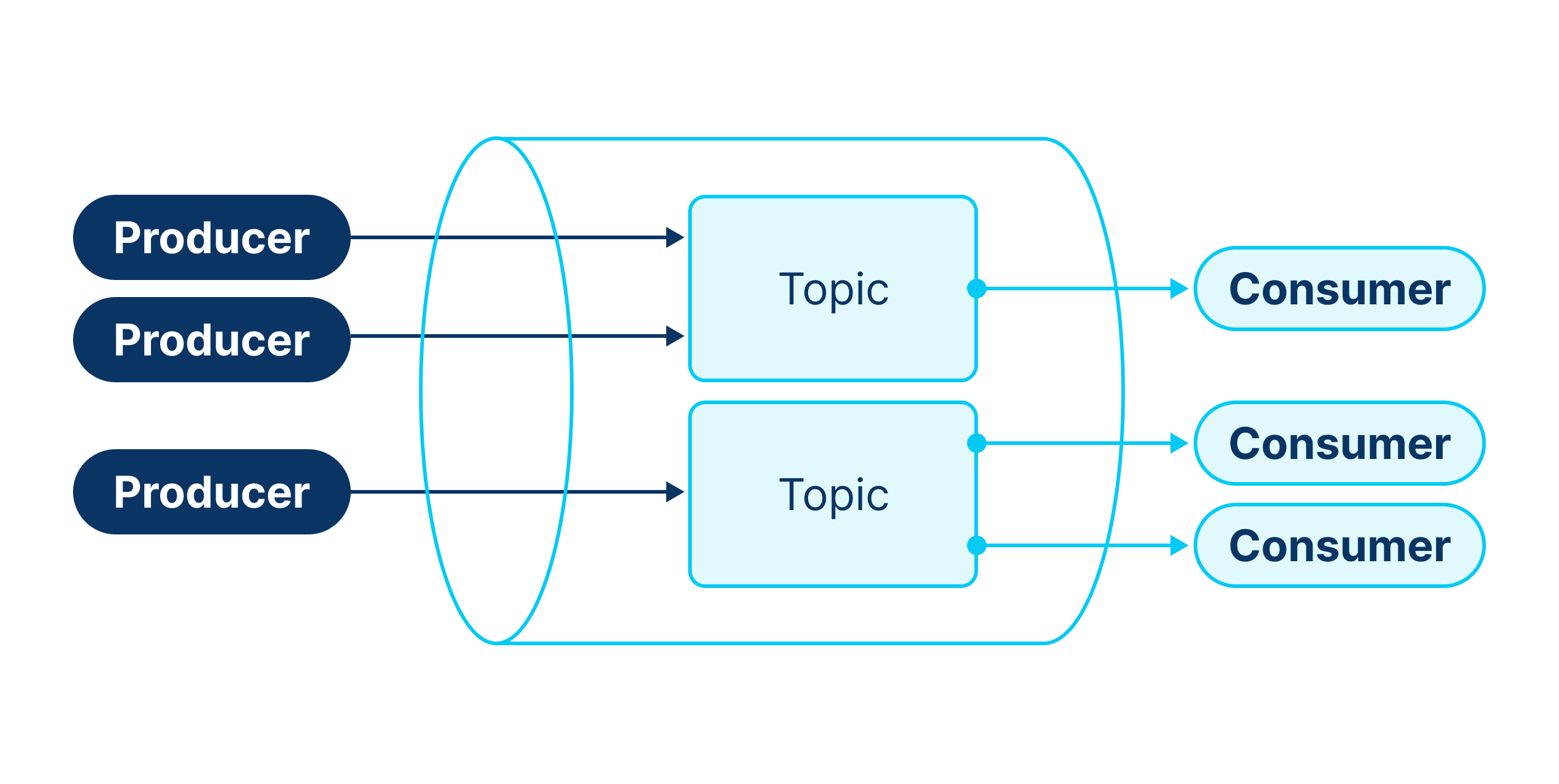
Compared to RabbitMQ, Kafka's routing capabilities are limited. It is not designed for granular routing but for high performance and scaling.
One important thing to note here:
In RabbitMQ, when a Consumer receives a message from a Queue, they "steal" it. If successfully acknowledged, other Consumers won't get the message. Kafka Consumers behave the same way if they are in the same Consumer Group. Consumer Group is a Kafka abstraction, which allows multiple Consumers to read from the same Topic independently, ensuring each Consumer Group processes all Topic messages.
Persistence and durability
In RabbitMQ, durability and persistence are distinct characteristics:
-
Durability. It is a property of Queues and Exchanges. There are two types of Queues: durable and transient. A durable Queue (or Exchange) stores its metadata on the disk and can survive a broker restart. Transient Queues do not.
-
Persistence. A durable Queue does not guarantee message durability. To make it durable, you must configure persistence. When the Publisher sends a message, it can specify the persistence property. In this case, a message will be stored in internal disk storage and be available after the broker restart.
Kafka stores everything on a disk. Unlike RabbitMQ, which deletes messages after Consumer acknowledgment, Kafka retains all messages until they reach a time-to-live (TTL) or disk size limit. It allows messages to be reprocessed by different or the same Consumer Group.
Scalability
Both RabbitMQ and Kafka support clustering, where multiple brokers work together.
In RabbitMQ, clustering improves availability and ensures data safety. If we talk about performance, then vertical scaling is a preferable way to boost your RabbitMQ. Horizontal scaling may add significant synchronization overhead. Typically, you would prefer having a 3-broker cluster to ensure availability in case one broker fails.
RabbitMQ does not support queue partitioning out of the box, but it is worth mentioning that it has
Kafka scales efficiently. Not only does it provide availability and data safety, but it also improves the throughput of data processing. The key concept here is partitioning. Each topic has a configurable number of partitions. Each partition operates in isolation from the others, acting as a physical data storage and processing. You can replicate each partition across the cluster, which ensures fault tolerance. Producers and consumers work only with the main (or primary) partition. If the broker with this partition goes down, the system elects a new primary partition from the replicas.
Choosing the right number of partitions is crucial. A large number of partitions slows system recovery in case of node failure. Conversely, it limits throughput and the level of parallelism for the consumer group. Within one consumer group, each partition can work with only one consumer (which is effectively one thread in your application). Therefore, having three partitions would make no sense to have more than three consumers because the rest will be idle.
Ordering
RabbitMQ guarantees ordering within a single queue. One consumer will process messages in order. However, the situation changes with multiple consumers. If one consumer fails, the system returns the unacknowledged messages to the queue, but the next consumer may already be processing the next batch. So, what are the options?
- Use Kafka! Kafka guarantees ordering within one partition (it is intuitive because it can work with one partition at a time). However, Kafka does not guarantee ordering for the entire topic. Usually, it is essential to maintain order within a customer ID or payment ID. So, if the producer uses the correct partition key, you can achieve accurate ordering for your system.
- Use
the consistent hash exchange plugin . With the Single-Active Consumer option, it transforms RabbitMQ into Kafka. It gives you "partitions" and ensures only one consumer can work with each partition.
Delivery guarantees
RabbitMQ and Kafka provide "at-least-once" delivery guarantees, meaning duplicates are possible, but messages will be fully processed at least once.
Kafka has more delivery features:
- Idempotent Producer. In Kafka, you can configure your Producer to replace duplicated messages. RabbitMQ Producer can send duplicates to the queue.
- Exactly-once delivery within Kafka processing. Exactly once - is the strongest guarantee. It ensures that each message will be processed just once, no more and no less. In Kafka, you can get it with Kafka transaction: when you consume from one Kafka topic and write to another Kafka topic.
Additional Features
As was mentioned before, by giving up routing flexibility, Kafka brings powerful features in return.
Kafka offers powerful streaming processing libraries:
- Kafka Streams. Allows real-time data processing and transformations within Kafka.
- KSQL. Provides a SQL-like interface to query and transform streaming data, creating durable table abstractions backed by Kafka topics.
With Kafka Streams, you can perform time aggregations on your topic and push the results to another topic or database.
Let’s imagine you have a topic with exchange rates across different currency pairs, and you want to aggregate an open-high-low-close chart (also OHLC) data within time periods (5 minutes, 30 minutes, 1 hour, etc.).
One option is to store data in a time-series database, which is suitable for such processing. However, you don’t need that if you have Kafka. Using simple Kafka Stream aggregations, you can calculate OHLC data on top of a Kafka topic and put the results into any database for further querying.
Kafka also allows you to represent processed messages as a table. It puts aggregation results into a table abstraction, which you can access via KSQL. Such a table state is durable. If a broker restarts, it will reinstate the latest state from the corresponding topic.
As we see, Kafka goes beyond basic message broker functionality and steps into the territory of real-time processing and ETLs.
Conclusion
Both Kafka and RabbitMQ are excellent tools for high-throughput, low-latency scenarios. The choice depends on the specifics of the use case, architecture, and future requirements. For example, Kafka is ideal for long-term transaction event storage, while RabbitMQ excels in scenarios requiring protocol compatibility and routing flexibility. When both RabbitMQ and Kafka are fit, consider your future needs.