

Authors:
(1) Omer Rathore, Department of Physics, Durham University;
(2) Alastair Basden, Department of Physics, Durham University;
(3) Nicholas Chancellor, Department of Physics, Durham University and School of Computing, Newcastle University;
(4) Halim Kusumaatmaja, Department of Physics, Durham University and Institute for Multiscale Thermofluids, School of Engineering, The University of Edinburgh.
Table of Links
Methods
Results
Conclusions and Outlook, Acknowledgements, and References
Smoothed Particle Hydrodynamics
This paper is not concerned with the technical details behind discretising a set of governing equations using the SPH operator, as this is application specific and the interested reader can refer to the relevant literature[18], [20]. Instead, the key takeaway here is the idea that this family of methods requires storage of particle data. Moreover these particles are irregularly positioned in space and move at each time step. Although this is a key strength of SPH as it allows particle aggregation in certain regions of interest and a sparse distribution in other areas, leveraging this benefit in practice is only viable with efficient memory and work allocation.
Compact support of the kernel ensures that particles are only influenced by neighbours that fall within the smoothing length. So it would be logical to split the domain into sections when assigning work to processors in order to limit inter-processor communication. However as the particles are disordered it is important to remember some regions will be more densely populated than others, thus there is also the second avenue of intra-processor communication to consider when creating a work distribution.
Classical data to be partitioned, by using QA in this work, was obtained via SWIFT[74], a popular astrophysics code that has demonstrated good scalability on 100,000 cores. SWIFT relies on task based parallelism[75] in order to optimise shared-memory performance within each individual node as its backbone. This can then be readily generalised to create a work allocation across multiple, distributed memory nodes using graph partitioning algorithms. In summary, the domain is initially divided into a set of cells, with each cell containing a collection of particles such that if two particles interact they are either in the same cell or at most neighbouring cells.
In terms of load balancing, this domain decomposition approach can be efficiently modeled as a graph, where each node symbolizes an individual cell containing some number of particles. The edges of this graph represent shared tasks reliant on particles located in separate cells that require communication between these cells. Moreover, tasks involving cells from different partitions must be processed by both respective processors, whereas tasks within the same partition are evaluated exclusively by the corresponding processor. An optimal load balancing strategy aims to minimize both the sum of node weights for each subset and the sum of edge weights bridging these subsets. The former goal is to reduce the waiting time caused by the slowest processor at each step, while the latter focuses on decreasing the necessary bandwidth for inter-processor communication. This dual objective ensures both efficient processing and minimal communication overhead.
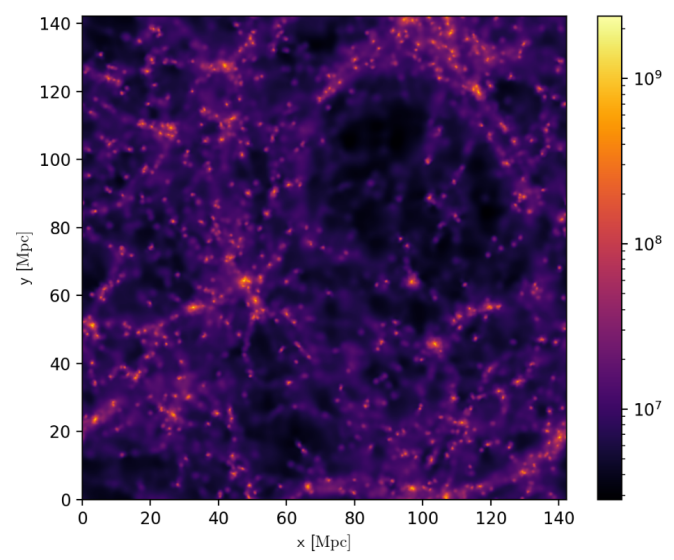
Values for the weights were obtained by simulating a small cosmological volume with dark matter as found in the SWIFT example suite and illustrated in Figure 3. The simulation involves 64[3] particles and the weights were extracted by timing the intra/inter cell tasks respectively for node/edge weights. The domain decomposition parameters were modified by design to reduce the number of cells in order to accommodate the problem onto current annealers. Since the cells are cubes, in three dimensions this boils down to a minimum node/cell count of 27 since each cell has 6 face adjacent, 12 edge adjacent and 8 corner adjacent neighbours. With all 26 neighbours residing within the 1 cell range defined earlier for shared tasks, this results in a fully connected graph.
The Ising model[22] for this load blancing problem places a spin variable (−1/+1) on each node in order to determine whether that node will eventually belong in the "+" or "−" subset. The energy functional consists of two components,

where a Lagrange parameter (γ) has been introduced to allow changing γ in order to explore any conflicting effects. The model includes a penalty term when the node weight in set + is not equal to that in set −,

where the sum is across all nodes, each with weight wi . Additionally there is a penalty term for each time an edge that connects nodes in different subsets is cut,

where the sum is across all edge connected nodes with ei referring to the weight of the edge. This is a NP-hard problem[73] of significant value in ensuring many particle based codes retain a meaningful advantage on future HPC systems. Currently SWIFT relies on the graph partitioning software METIS[76].
This paper is available on arxiv under CC BY 4.0 DEED license.