

Authors:
(1) Simon R. Davies, School of Computing, Edinburgh Napier University, Edinburgh, UK (s.davies@napier.ac.uk);
(2) Richard Macfarlane, School of Computing, Edinburgh Napier University, Edinburgh, UK;
(3) William J. Buchanan, School of Computing, Edinburgh Napier University, Edinburgh, UK.
Table of Links
- Abstract and 1 Introduction
- 2. Related Work
- 3. Methodology and 3.1. File Content Analysis
- 3.2. File Name Analysis
- 3.3. Executable Analysis
- 3.4. Behaviour Analysis
- 4. Evaluation and Discussion
- 4.1. Majority Voting
- 5. Conclusion
- 5.1. Limitations
- 5.2. Future Work
- References and Appendix
4. Evaluation and Discussion
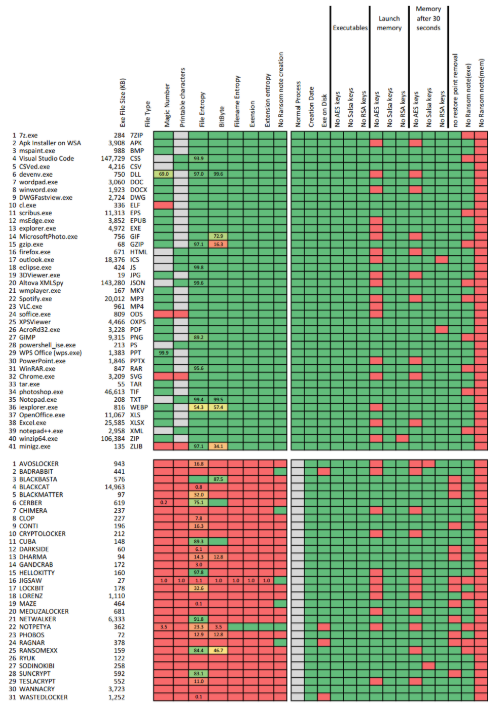
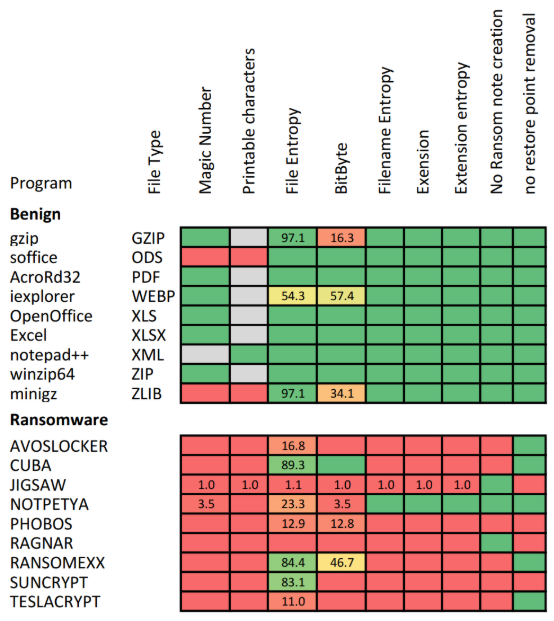
The majority of the recorded results for the tests described in Section 3 are provided in Figure 2. The cell colours represent the success of the test and are graded from green to red. 100% pass rate results are represented as a dark green colour, the colour changes depending on the success rate to red which indicates 0% pass rate, or alternatively 100% failure rate. Where the colour does not clearly show the result, then the percentage number is also displayed. Grey indicates that the specific test was not executed on that particular file type. For example, as mentioned above, if the file type should contain a magic number, then this test was performed and the printable character test was ignored.
Some of the tests were exploratory in nature in an attempt to discover if the gathered metrics could be used to identify malicious code. Examples of these exploratory tests were in the cataloguing of API calls distinguishable in the executable as well as the process memory directly after launch and then again 30 seconds after launch. The results of these tests are presented in Figures 3-6. The remainder of this section reviews the results gathered during the testing and provides some context, discussion and background into the tests and the recorded results. A clarification of a test’s success is provided in Table 3.
File content analysis. These tests were performed on the files generated by a process. These tests included the analysis of the created file’s magic number value, or for plain text files, the percentage of humanly readable characters within the file was analysed. Other tests included the Chi-Square entropy of the content of the file as well as the BitByte value test. Of all the tests performed these were some of the most successful in differentiating between output generated from benign and malicious processes, a summary of the results is provided in Table 4. No individual test achieved 100% accuracy but the BitByte test is worth highlighting as its results were more accurate than the plain entropy tests when working on files with unknown content. The magic number test combined with known file extension tests also achieved high accuracy, but these rely on the created files having a known extension. These tests could be bypassed, by ransomware using well-known extensions on their output, as highlighted by the results recorded when analysing the files generated by the NotPetya ransomware strain which does not modify the extension of the files it attacks [64].
Generated file name analysis. These tests were performed on the names of the files generated by the process. These tests included the analysis of the entropy of the entire filename, the entropy of the file name’s extension as well as validating if the file name’s extension was a known value. These tests also achieved high accuracy, a summary of the results is provided in Table 4. Contributing factors to this high accuracy was that the benign files used all had wellknown file extensions and almost all the tested ransomware strains modified the files name and/or extension in a way that increased the overall entropy of the filename. While the testing did cover more than 30 different ransomware strains, it may not be sufficiently broad enough to generalise this phenomenon. As with some of the file content tests, the exception being the files generated by the NotPetya ransomware strain, which was able to successfully evade this group of tests. This leads us to think that these tests should be applied to a larger test dataset, before generalising the findings.
Ransomnote tests. These tests can also be divided into static and dynamic analysis tests. The static portion of the tests involved examining the executable file used to launch the process and trying to identify several occurrences of typical strings used in ransom notes. This analysis could be performed prior to the launching of the process. In one of the dynamic analysis tests, the running process’s volatile memory was examined for the existence of these same ransom note strings. In the other dynamic analysis test, the files generated by the process were examined to determine if the file being created could possibly be a ransom note. No ransom note strings were found in either the begin or ransomware executable binaries. The success rate when looking for ransom note strings within the memory was very low with positive matches only 20% of the time. These matches were relatively evenly distributed between benign and malicious programs. A consequence of this is that it seems that these metrics would not be suitable for use within a ransomware detection program. The accuracy may be improved for these tests by possibly applying some additional logic to the search, for example, by increasing the dictionary of keywords being searched for, applying natural language processing on the found strings, or analysing the distance between where
these words appear and applying a ranking or weighting to the found strings.
The results regarding the dynamic test of analysing the contents of files being created by the process were much more encouraging. No files generated by the benign programs were marked as ransomware, and 80% of the ransom notes generated by the ransomware were successfully identified. Some reasons why this rate was not even higher were that some ransomware strains do not create ransom notes, some ransom notes were actual graphics and some ransomware strains changed the desktop background to display the ransom message. This is a promising finding as many ransomware strains create the ransom note prior to the encryption [47] of the data and a successful interception at this point in the attack would be beneficial.
Identification of cryptographic artefacts. These tests involved attempting to identify cryptographic algorithm artefacts using both static and dynamic analysis methods. The static portion of the tests involved looking for these artefacts in the executable binary files used to launch the process. This analysis could be performed prior to the launching of the process. The dynamic aspect of these tests involved looking for these artefacts in the process’s volatile memory, precisely after the process has been launched and then again 30 seconds after the process’s launch. The artefacts that were being searched for were AES encryption algorithm keys of length 128 bits, 192 bits and 256 bits, as well as RSA asymmetric and Salsa20 encryption algorithm keys. This resulted in 15 distinct tests per file type resulting in a total of more than 1,000 tests being conducted for this group of tests. When reviewing the results it can be seen that no cryptographic artefacts were identifiable in any of the test binaries. Regarding the AES key discovery, then no real pattern could be identified. For benign programs, these keys were identified in 44% of the samples and with ransomware programs, these keys were identified in 35% of the samples. These findings indicate that this metric in its current format is not particularly suited for indicating ransomware activity. It is a known behaviour, that ransomware does use cryptography during its execution, so some explanation for the lack of successful key identification could be that these algorithms are not used in these ransomware samples or that the encryption has either not commenced or has completed when the analysis was performed. The presence of these artefacts in memory of benign programs is not ideal as it complicates the metric.
Behavioural analysis. These tests are aimed at analysing the behaviour of the process under investigation. The idea behind the first test, normal process, was to try and identify if a running process attempts to alter its execution privileges and try and run as an elevated user. None of the benign processes did this, however, many of the ransomware samples used, would not execute correctly without them being started as the administrator user, which negated the usefulness of this test. No identifying trend could be used to differentiate benign and malicious binary files using the file
creation date. With regards to file-less execution, four ransomware samples did spawn a malicious process that had no underlying binary file on disk and approximately 45% of ransomware programs removed system restore points soon after they started executing. Both these last two behaviours were only observed with ransomware programs and could be used as a contributing factor when trying to determine if the process is malicious or not.
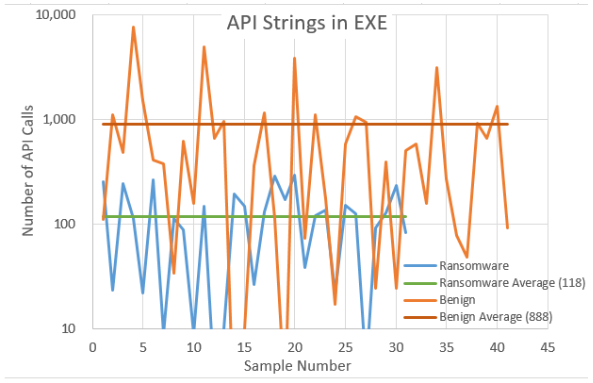
Analysis Tests. Some exploratory investigation was also performed in cataloguing and analysing the number and frequency of standard Windows API calls within both the binary executable file (static analysis) as well as the process’s volatile memory (dynamic analysis) directly after launch and then again 30 seconds after launch. Note that the Y-axis on the following figures has a logarithmic scale. From Figure 3, it can be seen that the number of API calls present in the executables of benign programs differ by a factor of eight when compared to the number of API calls identified within ransomware programs One possible explanation for this could be that ransomware programs often try and obfuscate their structure prior to execution in an attempt to hinder analysis and a consequence of this being that the API calls are hidden.
To normalise these results, the values were then plotted as a ratio of the number of API calls present divided by the analysed executable file size. These normalised results are shown in Figure 4 The programs were then launched and the volatile memory used by each of these programs was then captured and analysed for Windows API calls. A comparison of the API calls present within each process’s memory is presented in Figure 5. Again to aid comparison, the graphs have been normalised by dividing the total number of calls by the size of the total memory being used. Finally, the launched program’s memory was captured again 30 seconds after launch and analysed for Windows API calls. A comparison of the API calls present within each process’s memory is presented in Figure 6 with the results being normalised.
When reviewing the captured results, it can be seen that the identified API calls within the binary files show signs of possibly being a useful indicator of Windows API obfuscation and thus an indicator of a possibly malicious program.
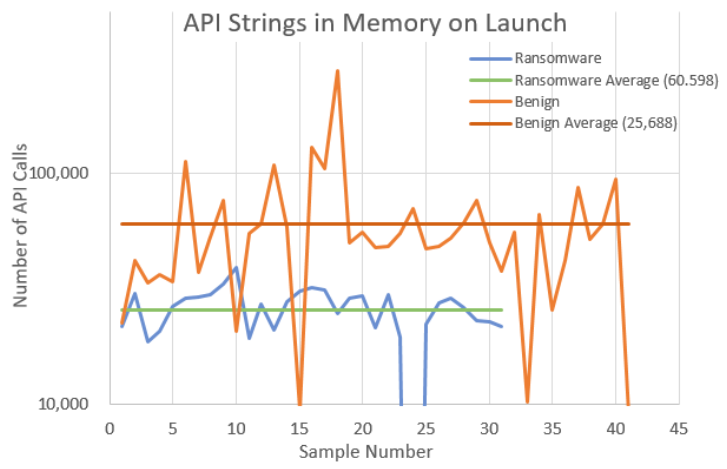
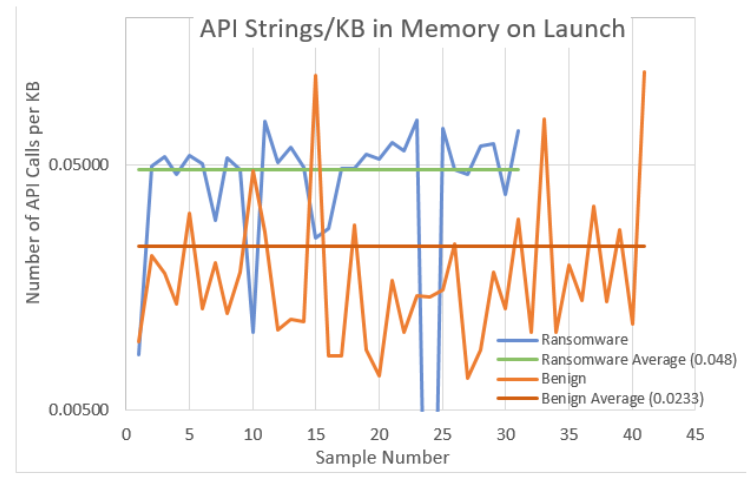
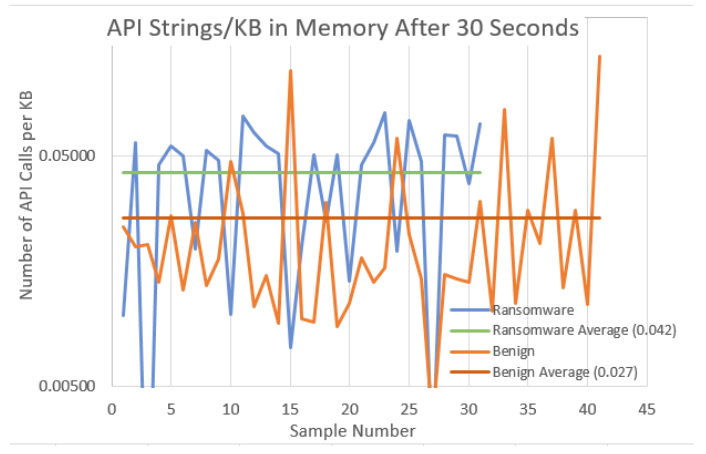
The measurements show that there is an obvious difference between the number of API calls found within the benign and malicious executables. The difference between these two types of executables is not so prominent when analysing the process’s volatile memory. However, it is felt by the researchers that these findings merit further investigation. As they stand, using the current metrics, these results would not prove useful as a contributor to the suite of tests used in the malice score calculation. Some refinement of the measurement, such as targeting specific API calls or call frequency analysis may enhance the accuracy of this type of measurement and further investigation into this would be beneficial.
This paper is available on arxiv under CC BY 4.0 DEED license.