

Authors:
(1) Michael Moor, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(2) Qian Huang, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(3) Shirley Wu, Department of Computer Science, Stanford University, Stanford, USA;
(4) Michihiro Yasunaga, Department of Computer Science, Stanford University, Stanford, USA;
(5) Cyril Zakka, Department of Cardiothoracic Surgery, Stanford Medicine, Stanford, USA;
(6) Yash Dalmia, Department of Computer Science, Stanford University, Stanford, USA;
(7) Eduardo Pontes Reis, Hospital Israelita Albert Einstein, Sao Paulo, Brazil;
(8) Pranav Rajpurkar, Department of Biomedical Informatics, Harvard Medical School, Boston, USA;
(9) Jure Leskovec, Department of Computer Science, Stanford University, Stanford, USA.
Table of Links
6 Discussion, Acknowledgments, and References
ABSTRACT
Medicine, by its nature, is a multifaceted domain that requires the synthesis of information across various modalities. Medical generative vision-language models (VLMs) make a first step in this direction and promise many exciting clinical applications. However, existing models typically have to be fine-tuned on sizeable down-stream datasets, which poses a significant limitation as in many medical applications data is scarce, necessitating models that are capable of learning from few examples in real-time. Here we propose Med-Flamingo, a multimodal few-shot learner adapted to the medical domain. Based on OpenFlamingo-9B, we continue pre-training on paired and interleaved medical image-text data from publications and textbooks. Med-Flamingo unlocks few-shot generative medical visual question answering (VQA) abilities, which we evaluate on several datasets including a novel challenging open-ended VQA dataset of visual USMLE-style problems. Furthermore, we conduct the first human evaluation for generative medical VQA where physicians review the problems and blinded generations in an interactive app. Med-Flamingo improves performance in generative medical VQA by up to 20% in clinician’s rating and firstly enables multimodal medical few-shot adaptations, such as rationale generation. We release our model, code, and evaluation app under https://github.com/snap-stanford/med-flamingo.
1 INTRODUCTION
Large, pre-trained models (or foundation models) have demonstrated remarkable capabilities in solving an abundance of tasks by being provided only a few labeled examples as context Bommasani et al. (2021). This is known as in-context learning Brown et al. (2020), through which a model learns a task from a few provided examples specifically during prompting and without tuning the model parameters. In the medical domain, this bears great potential to vastly expand the capabilities of existing medical AI models Moor et al. (2023). Most notably, it will enable medical AI models to handle the various rare cases faced by clinicians every day in a unified way, to provide relevant rationales to justify their statements, and to easily customize model generations to specific use cases.
Implementing the in-context learning capability in a medical setting is challenging due to the inherent complexity and multimodality of medical data and the diversity of tasks to be solved.
Previous efforts to create multimodal medical foundation models, such as ChexZero Tiu et al. (2022) and BiomedCLIP Zhang et al. (2023a), have made significant strides in their respective domains. ChexZero specializes in chest X-ray interpretation, while BiomedCLIP has been trained on more diverse images paired with captions from the biomedical literature. Other models have also been developed for electronic health record (EHR) data Steinberg et al. (2021) and surgical videos Kiyasseh et al. (2023). However, none of these models have embraced in-context learning for the multimodal medical domain. Existing medical VLMs, such as MedVINT Zhang et al. (2023b), are typically trained on paired image-text data with a single image in the context, as opposed to more general
streams of text that are interleaved with multiple images. Therefore, these models were not designed and tested to perform multimodal in-context learning with few-shot examples[1]
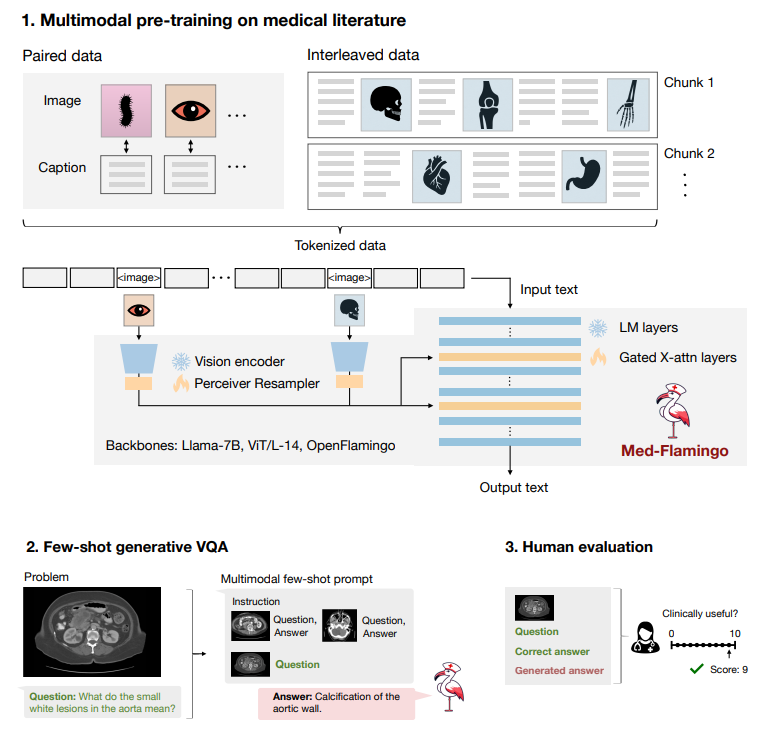
Here, we propose Med-Flamingo, the first medical foundation model that can perform multimodal incontext learning specialized for the medical domain. Med-Flamingo is a vision-language model based on Flamingo (Alayrac et al., 2022) that can naturally ingest data with interleaved modalities (images and text), to generate text conditioned on this multimodal input. Building on the success of Flamingo, which was among the first vision-language models to exhibit in-context learning and few-shot learning abilities, Med-Flamingo extends these capabilities to the medical domain by pre-training on multimodal knowledge sources across medical disciplines. In preparation for the training of Med-Flamingo, our initial step involved constructing a unique, interleaved image-text dataset, which was derived from an extensive collection of over 4K medical textbooks (Section 3). Given the critical nature of accuracy and precision within the medical field, it is important to note that the quality, reliability, and source of the training data can considerably shape the results. Therefore, to ensure accuracy in medical facts, we meticulously curated our dataset from respected and authoritative sources of medical knowledge, as opposed to relying on potentially unreliable web-sourced data.
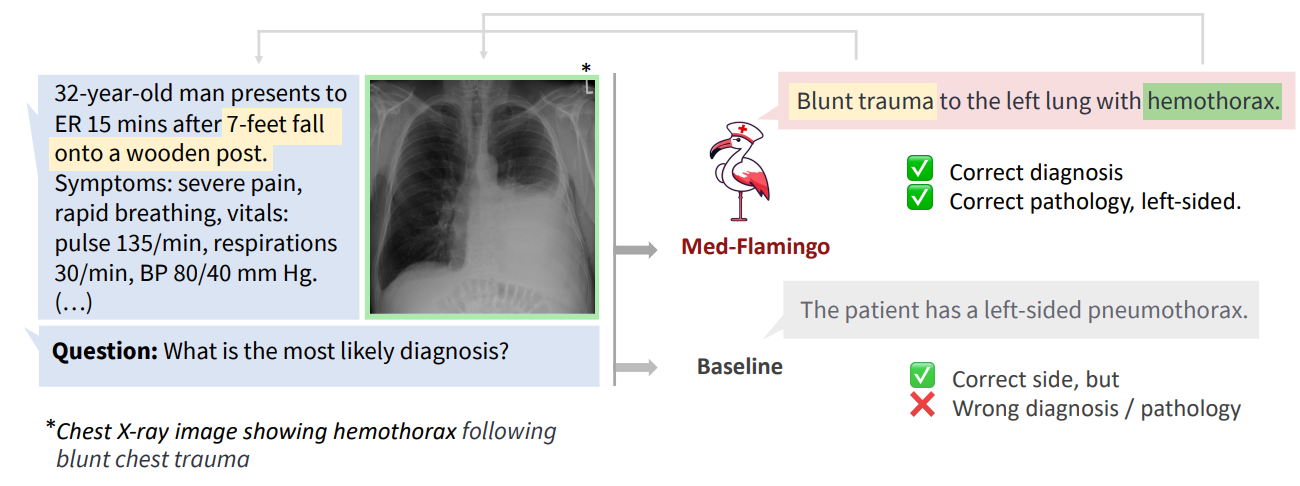
In our experiments, we evaluate Med-Flamingo on generative medical visual question-answering (VQA) tasks by directly generating open-ended answers, as opposed to scoring artificial answer options ex post–as CLIP-based medical vision-language models do. We design a new realistic evaluation protocol to measure the model generations’ clinical usefulness. For this, we conduct an in-depth human evaluation study with clinical experts which results in a human evaluation score that serves as our main metric. In addition, due to existing medical VQA datasets being narrowly focused on image interpretation among the specialties of radiology and pathology, we create Visual USMLE, a challenging generative VQA dataset of complex USMLE-style problems across specialties, which are augmented with images, case vignettes, and potentially with lab results.
Averaged across three generative medical VQA datasets, few-shot prompted Med-Flamingo achieves the best average rank in clinical evaluation score (rank of 1.67, best prior model has 2.33), indicating that the model generates answers that are most preferred by clinicians, with up to 20% improvement over prior models. Furthermore, Med-Flamingo is capable of performing medical reasoning, such as answering complex medical questions (such as visually grounded USMLE-style questions) and providing explanations (i.e., rationales), a capability not previously demonstrated by other multimodal medical foundation models. However, it is important to note that Med-Flamingo’s performance may be limited by the availability and diversity of training data, as well as the complexity of certain medical tasks. All investigated models and baselines would occasionally hallucinate or generate low-quality responses. Despite these limitations, our work represents a significant step forward in the development of multimodal medical foundation models and their ability to perform multimodal in-context learning in the medical domain. We release the Med-Flamingo-9B checkpoint for further research, and
make our code available under https://github.com/snap-stanford/med-flamingo. In summary, our paper makes the following contributions:
-
We present the first multimodal few-shot learner adapted to the medical domain, which promises novel clinical applications such as rationale generation and conditioning on retrieved multimodal context.
-
We create a novel dataset that enables the pre-training of a multimodal few-shot learner for the general medical domain.
-
We create a novel USMLE-style evaluation dataset that combines medical VQA with complex, across-specialty medical reasoning.
-
We highlight shortcomings of existing evaluation strategies, and conduct an in-depth clinical evaluation study of open-ended VQA generations with medical raters using a dedicated evaluation app.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
[1] For example, a challenge with multimodal in-context learning for existing medical vision language models is the potential for image information to leak across examples, potentially misleading the model.