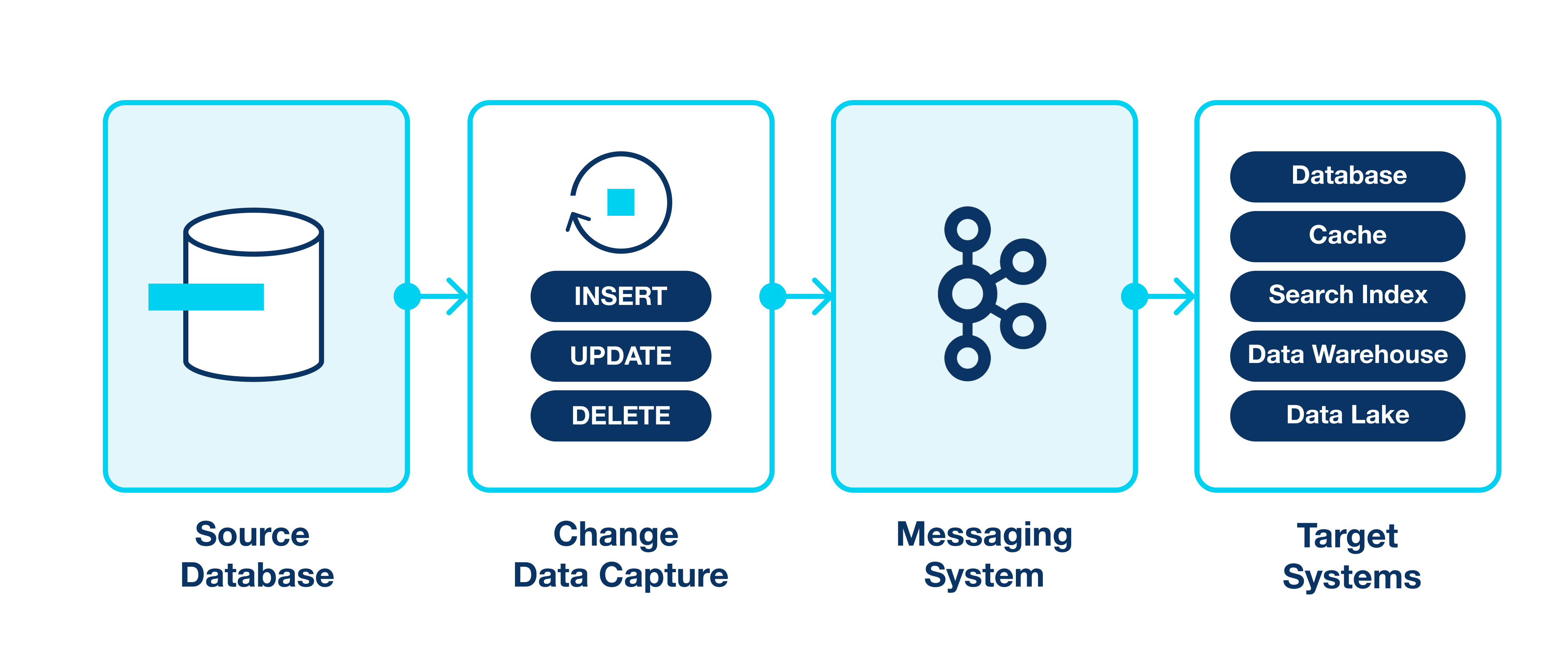
CDC stands for Change Data Capture. The idea of the CDC is to track changes in the database, capture, transform (optionally), and send them to the message queue for further processing. It is an underrated pattern that you can apply to solve various technical problems and challenges. In this article, we will look into the applications of the CDC pattern.
CDC pattern implementations
When it comes to CDC implementation, Kafka with Kafka Connect is a way to go.
Of course, there are other alternatives.
For example, you can implement the CDC pattern by yourself, detecting data changes in the domain service and publishing corresponding messages to a message broker or a database. However, this adds more complexity to the application and creates maintenance overhead. It also presents challenges in ensuring delivery guarantees (avoiding duplicated or missed messages) and ordering guarantees.
Another alternative is using Informatica. However, Informatica is not open source and requires an expensive license. Also, it is a relatively “heavy” tool.
Kafka Connect
Let's explore Kafka Connect and its role in CDC implementation.
Kafka Connect:
Kafka Connect is a tool that guarantees scalable and reliable streaming between source and Kafka AND between Kafka and target. It fully encapsulates communication with Kafka.
By itself, Kafka Connect does not know how to operate with source or target. Plugins do it. A plugin is a jar (or set of jars) that implements Kafka Connect connector logic. There are two types of connectors:
- Source connector. Describes how to collect data from the source (e.g., collect entire DB tables, etc.)
- Sink connector. Describes how to export data to the target. For example, it can be a Prometheus connector, which sends collected metrics to Prometheus.
Kafka Connect is a distributed system. It means you can deploy it with multiple instances. Each instance is called a worker. It solves two issues: fault tolerance and scalability.
- Fault tolerance. In case of failure of one worker, tasks are redistributed to the remaining workers, ensuring fault tolerance.
- Scalability. Additional workers can handle high throughput. Workers can process topic partitions in parallel, which contributes to scalability.
There are more interesting concepts and features in Kafka Connect, such as converters, transforms, and many more. They won't be covered in this article, but they are well described in the official documentation.
CDC Kafka Connect connectors
In CDC, we should consider two connector plugins - Debezium and JDBC. Let's compare them based on their characteristics.
|
Debezium |
JDBC |
|---|---|
|
Log-based change data capture (CDC), also known as true CDC, involves Debezium source connectors working at a low level by reacting to DB log files. That means that it has minimal influence on DB and high accuracy. For example, the Postgres connector uses logical decoding, and the Mongo connector uses native replication mechanisms. |
Not really a CDC. It works by polling corresponding tables comparing the lastUpdate timestamp field. So, it is required for tables to have such a field and update it every time the row is updated. Polling may create additional load. |
|
Supports various DBs, including both SQL and NoSQL. |
Supports DBs with JDBC. |
|
If a system operates normally, Debezium provides exactly-once delivery. In general, it is at-least-once delivery. |
At-least-once delivery. |
|
Low latency. |
In general, latency is higher and depends on polling intervals. |
|
The initial snapshot could be an issue. |
No issues. |
|
Each database has its own connector with a specific configuration. |
Easier to configure. |
|
More details on data change. However, because of its low-level nature, Debezium works only with physical data representation. |
It works with both logical (views) and physical representations (tables). It is just SQL polling. |
Scenarios of using CDC patterns
Here, I will describe three CDC pattern usage examples from my experience.
Outbox pattern
The Outbox pattern is a popular pattern in microservice architecture.
The idea is simple. Let's imagine you have two services: TransactionService and NotificationService. TransactionService is responsible for managing transactions. It adds and updates records (transactions) in the corresponding table, for example, in Postgres.
NotificationService is responsible for sending notifications to customers. It does not know much about the domain and operates with input messages (basically provides send(Id customerId, Message message) method).
Now, we want to notify a customer about transaction changes. For example, it could be a new transaction or a status change of an existing transaction.
There are multiple ways to implement this. For example, call NotificationService from TransactionService. But this is not the best approach. We need to ensure that the message will be sent at-least-once (ideally exactly-once). So, we need some asynchronous mechanism to achieve this.
Outbox pattern solves that using Outbox table and event bus (and Kafka can easily handle it). Let's see what it's going to look like:
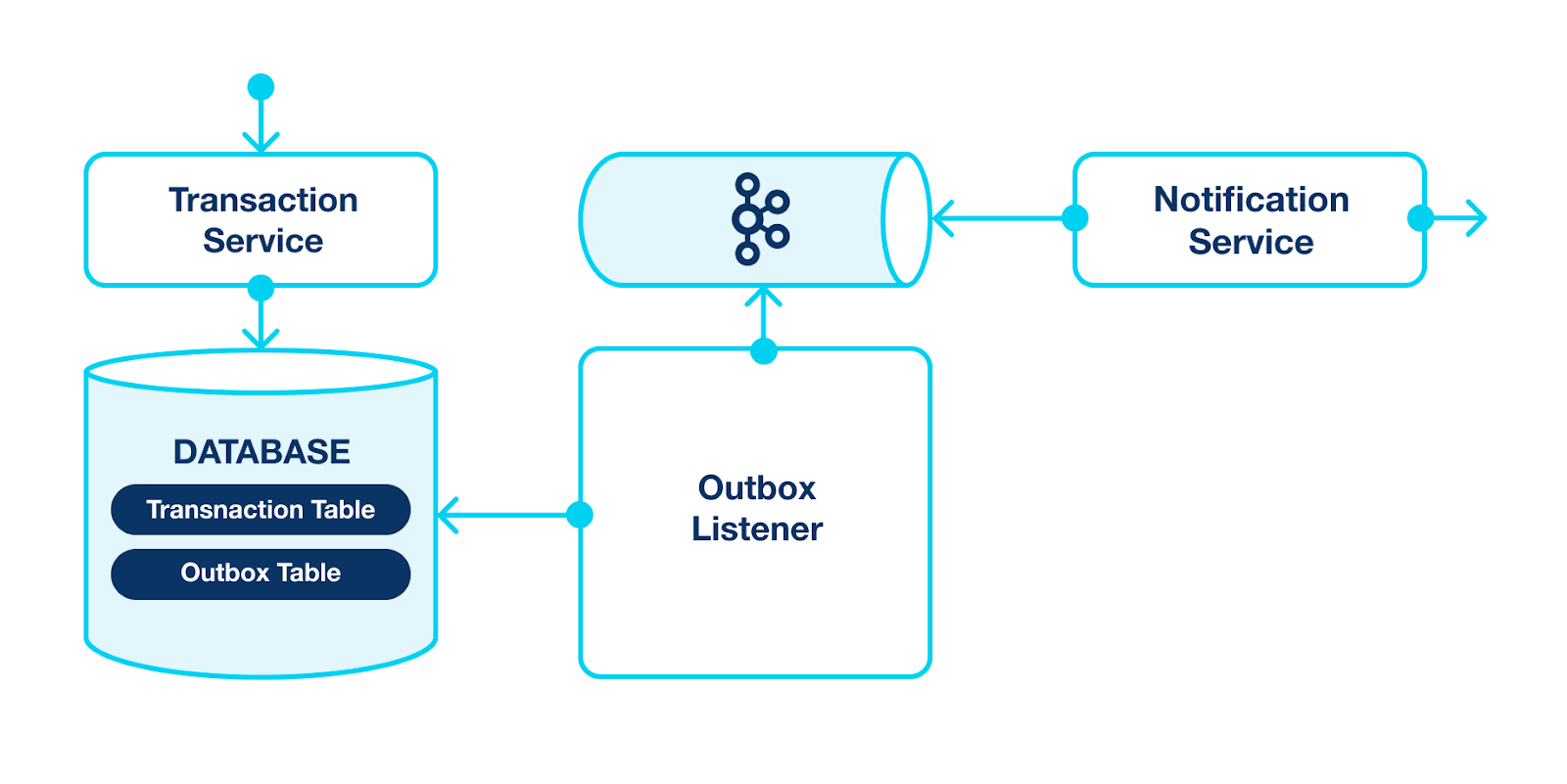
Steps:
- Transaction Service updates the Transaction Table and, within the same transaction, puts a new event into the Outbox Table. This event further should be handled by the Notification Service.
- We have a new component: Outbox Listener. It is a service that tracks the Outbox Table and pushes events to Kafka.
- Finally, the Notifications Service is a Kafka Consumer. Even if it is temporarily unavailable, it can process and handle events later on.
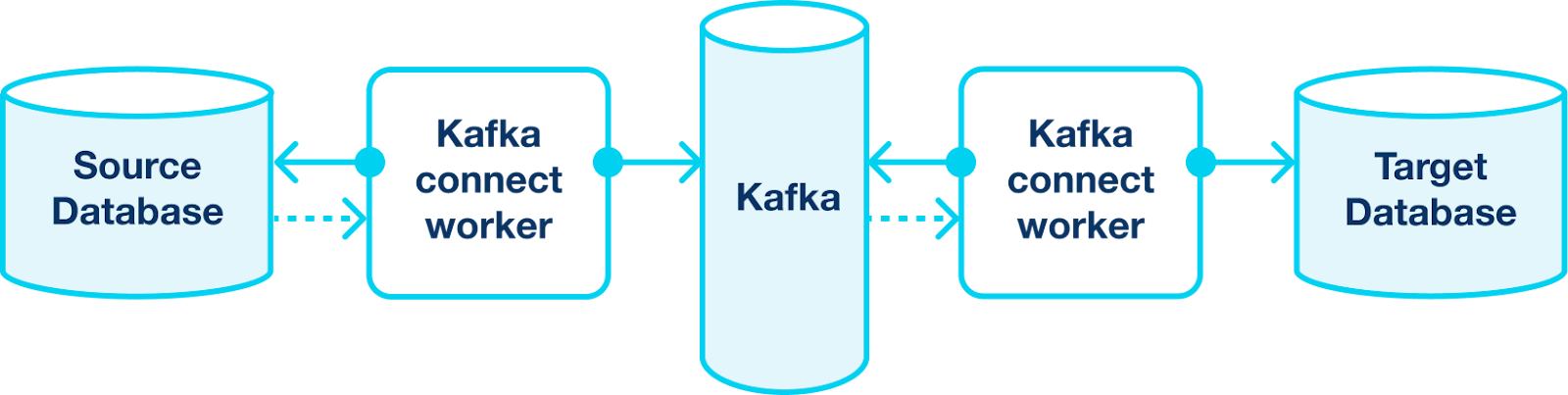
The main problem in this solution is the Outbox Listener. It should poll the Outbox Table and guarantee all events with changes are pushed to Kafka. Ideally, avoid duplicates. But you already know that CDC exists to solve such problems. It can easily replace the Outbox Lister in this scheme and provide better performance and delivery guarantees.
Here is what the scheme will look like:
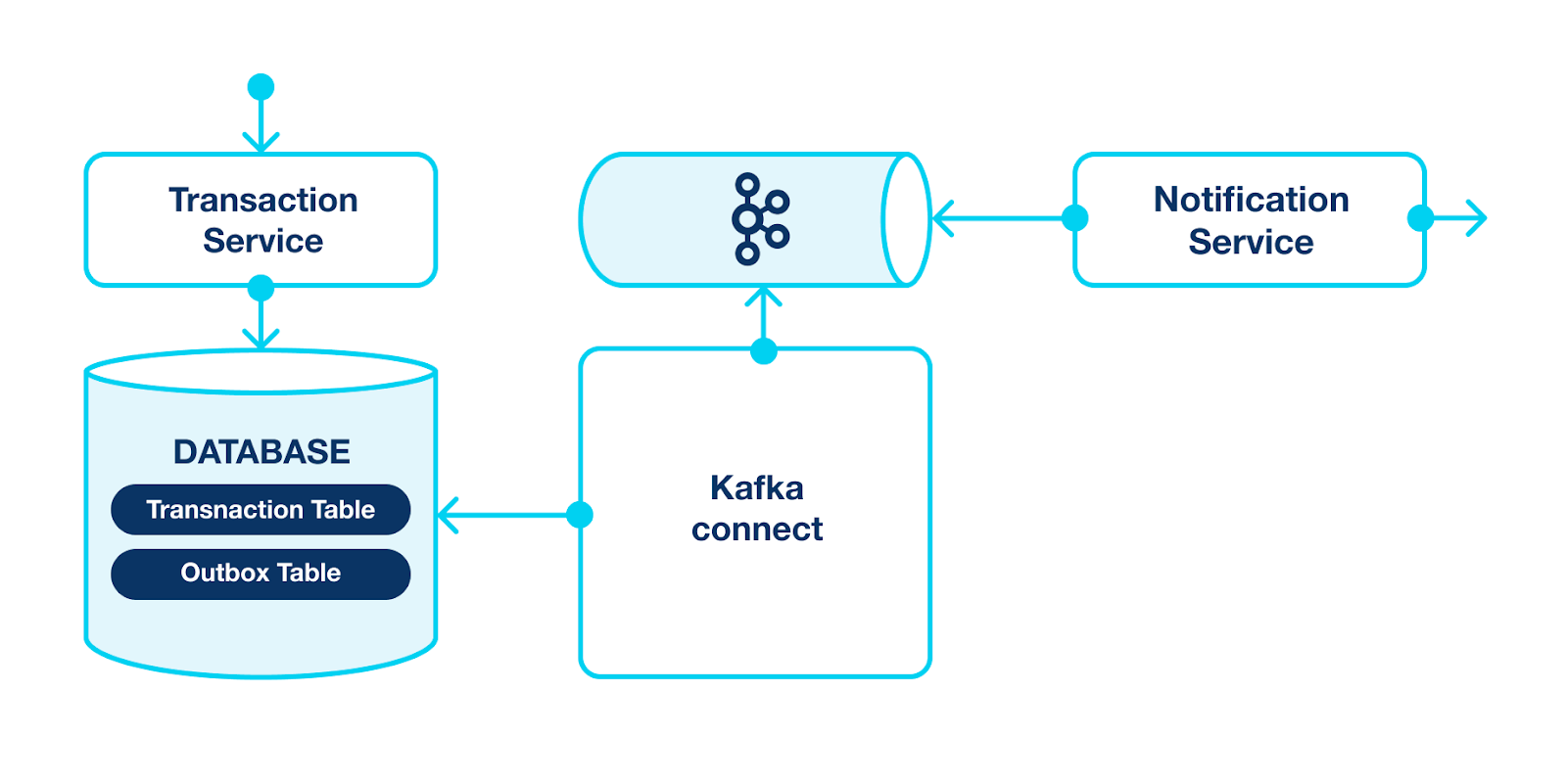
As you can see, Kafka Connect stands directly between source and Kafka AND between Kafka and target. It fully encapsulates communication with Kafka, making the solution more effective.
CQRS pattern with CDC
The CQRS (command query responsibility segregation) pattern says that the data mutation (write/update/delete operations) should be separated from the data query (read operations).
The CQRS pattern applies on different abstraction levels, but we will discuss the highest one, specifically services and databases. The pattern can be interpreted this way: for write operations use a database that suits your writes, and for read operations use a database that suits your reads. Indeed, in some cases, using the same database for writes and reads may be painful.
Imagine that you use RDBMS to store data. You have intensive write operations and read operations. At some point, there is a need for optimizations for both write operations and read operations. However, these optimizations often contradict each other. Optimizing reads requires more indexes, materialized views, and so on. But these actions can slow down write operations, and vice versa.
Or another situation. You choose a database for your project, and you plan that it will perform analytical aggregation operations. To achieve this, you require an OLTP database, but it does not have enough throughput for write operations.
From the examples above, you can see that the problems may be solved if one database handles write operations while the other handles reads. It is essentially what the CQRS pattern teaches us.
And CDC with Kafka Connect can be a great help here. It can track all changes in the write database and send them to the read database. Of course, there will be small latency, which may cause minor inconsistency, but considering that usually heavy query operations do not require such guarantees, it may not be an issue. Here is what it may look like:
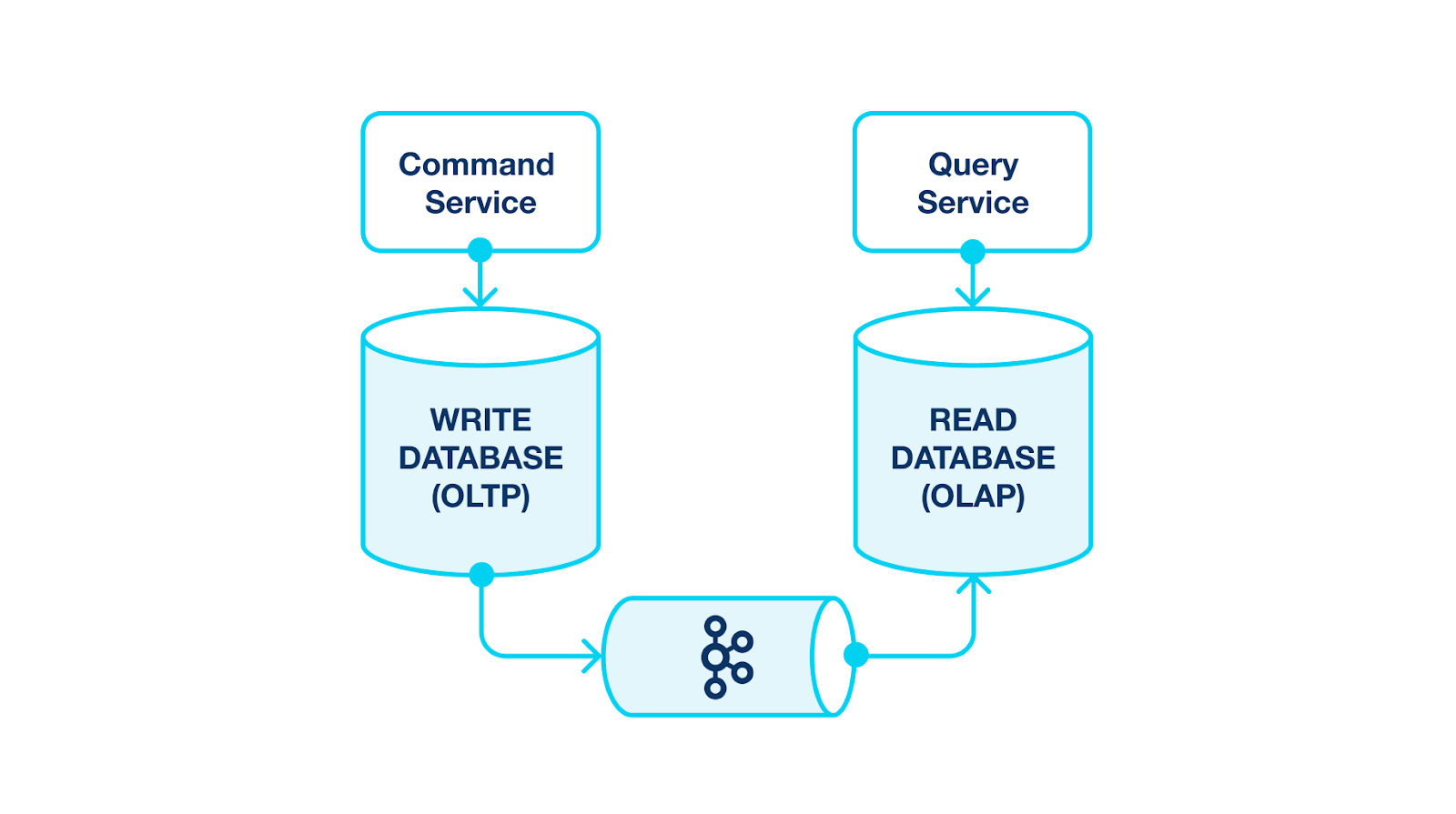
Steps:
- Command Service responsible for writing. It mainly writes data to the Write Database. For example, it can be any RDBMS.
- We must track changes to the tables we want to query. For Kafka Connect with Kafka, we can use the Source connector.
- The Sink connector gets updates from Kafka and pushes corresponding changes to the target Read Database. It can be any OLAP database that suits our query needs.
- The Query Service efficiently queries data. We segregate Command and Query services. Write and read operations are executed independently on different databases without interfering with each other.
Database Replication
Database replication is another challenge where the CDC pattern can be very useful.
It's common to need to move our cluster to new hosts due to various reasons such as hardware updates, cloud/data center changes, or security requirements. Alternatively, you may want to have a standby copy of your database. All these cases necessitate database replication.
It's not a trivial feature, and most community versions of databases lack it. For example, this is the case for Elasticsearch, GridGain, and MongoDB (although MongoDB recently released a migration tool, it doesn't guarantee full functionality with the community version).
One option is to go and upgrade your license - fair enough. But, unfortunately, it is not a suitable option in many cases.
Let's have a look at two real-life examples of database migration.
ElasticSearch migration
The first one is about ElasticSearch migration. It was a 5-node cluster with hundreds of gigabytes of data. The objective was to move the cluster from one subnet to another. Since data replication required additional licensing, it was decided to perform the cluster migration manually. The approach was as follows:
- Make a snapshot of the entire database.
- Add a new node to the cluster.
- Force shards migration to that node, emptying one of the existing old nodes.
- Exclude the old node.
- Repeat four times more.
As you can imagine, it took several hours for snapshot creation and even more hours for migration itself. The downtime was significant, and every step was risky.
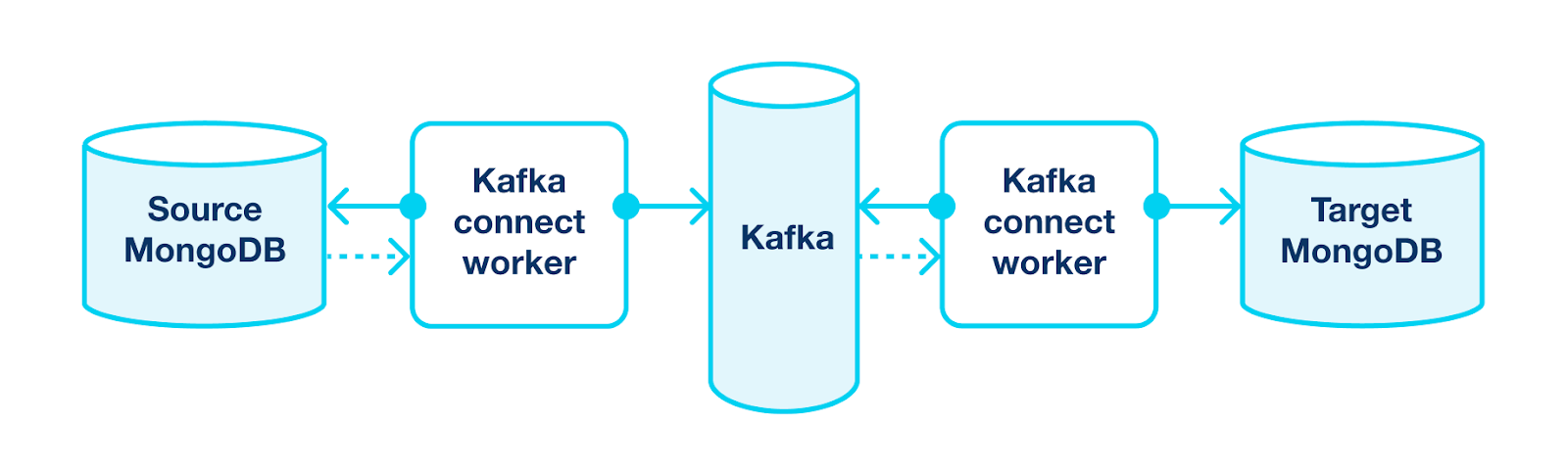
MongoDB migration
The second story is similar, but we were migrating a MongoDB cluster. The experience with Elasticsearch was so painful that we decided to find another solution. And we found it: CDC! Previously, we had used CDC for CQRS, so we already had all the necessary infrastructure - Kafka Connect with Kafka. All we needed to do was:
- Deploy the MongoDB cluster with a similar configuration in a new subnet.
- Add a simple connector configuration and specify the list of the MongoDB collections we wanted to replicate to Kafka Connect.
- The data started to replicate.
The replication latency was very low, so we just needed to switch services from the old cluster to the new one, and Voilà everything is ready!