

Authors:
(1) Rui Duan University of South Florida Tampa, USA (email: ruiduan@usf.edu);
(2) Zhe Qu Central South University Changsha, China (email: zhe_qu@csu.edu.cn);
(3) Leah Ding American University Washington, DC, USA (email: ding@american.edu);
(4) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu);
(5) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu).
Table of Links
Parrot Training: Feasibility and Evaluation
PT-AE Generation: A Joint Transferability and Perception Perspective
Optimized Black-Box PT-AE Attacks
APPENDIX
A. Speaker Recognition Models
1) Speaker Recognition Mechanisms: Speaker recognition models[6], [5], [86], [67] are typically categorized into statistical models, such as Gaussian-Mixture-Model (GMM) based Universal Background Model (UBM) [96] and i-vector probabilistic linear discriminant analysis (PLDA) [38], [85], and deep neural network (DNN) models [68], [41]. There are three phases in speaker recognition.
- In the training phase, one key component is to extract the acoustic features of speakers, which are commonly represented by the encoded low-dimensional speech features, (e.g., i-vectors [38] and X-vectors [100]). Then, these features can be trained by a classifier (e.g., PLDA [57]) to recognize different speakers.
2) During the enrollment phase, to make the classifier learn a speaker’s voice pattern, the speaker usually needs to deliver several text-dependent (e.g., Siri [3] and Amazon Echo [1]) or text-independent speech samples to the speaker recognition system. Depending on the number of enrolled speakers, speaker recognition tasks [29], [118], [113] can be (i) multiple-speaker-based speaker identification (SI) or (ii) single-speaker-based speaker verification (SV).
3) In the recognition phase, the speaker recognition model will predict the speaker’s label or output a rejection result based on the similarity threshold. Specifically, SI can be divided into close-set identification (CSI) and open-set identification (OSI) [39], [29]. The former predicts the speaker’s label with the highest similarity score, and the latter only outputs a prediction when the similarity score is above the similarity threshold or gives a rejection decision otherwise. SV only focuses on identifying one specific speaker. If the similarity exceeds a predetermined similarity threshold, SV returns an accepted decision. Otherwise, it will return a rejection decision.




B. Comparison of PT and GT Models
Constructing PT models: There are multiple ways to set up and compare PT and GT models. We set up the models based on our black-box attack scenario, in which the attacker knows that the target speaker is trained in a speaker recognition model but does not know other speakers in the model. We first build a GT model using multiple speakers’ speech samples, including the target speaker’s. To build a PT model for the attacker, we start from the only information that the attacker is assumed to know (i.e., a short speech sample of the target speaker), and use it to generate different parrot speech samples. Then, we use these parrot samples, along with speech samples from a small set of speakers (different from the ones used in the GT model) in an open-source dataset, to build a PT model.
We use CNN and TDNN to build two GT models, called CNN-GT and TDNN-GT, respectively. Each GT model is trained with 6 speakers (labeled from 1 to 6) from LibriSpeech (90 speech samples for training and 30 samples for testing for each speaker). We build 6 CNN-based PT models, called CNN-PT-i, and 6 TDNN-based PT models, called TDNN-PTi, where i ranges from 1 to 6 and indicates that the attacker’s targets speaker i in the GT model and uses only one of his/her speech samples to generate parrot samples, which are used together with samples from other 3 to 8 speakers randomly selected from VCTK (none is in the GT models), to train a PT model.
Evaluation metrics: We aim to compare the 12 PT models with the 2 GT models when recognizing the attacker’s target speaker. Existing studies [71], [66] have investigated
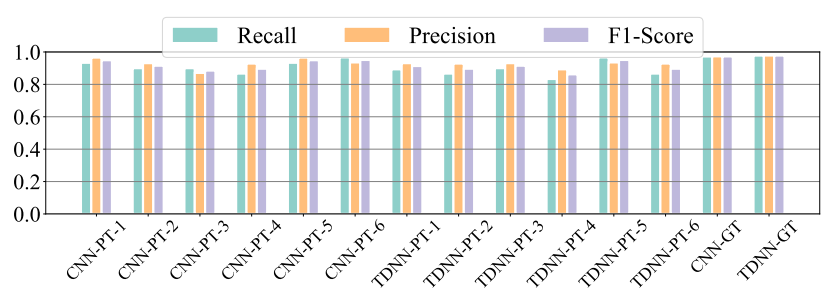
how to compare different machine learning models via the classification outputs. We follow the common strategy and validate whether PT models have the performance similar to GT models via common classification metrics, including Recall [37], Precision [45], and F1-Score [84], where Recall measures the percentage of correctly predicted target speech samples out of the total actual target samples, Precision measures the proportion of the speech which is predicted as the target label indeed belongs to the target speaker, and F1-Score provides a balanced measure of a model’s performance which is the harmonic mean of the Recall and Precision. To test each PT model (targeting speaker i) and measure the output metrics compared with GT models, we use 30 ground-truth speech samples of speaker i from LibriSpeech and 30 samples of every other speaker from VCTK in the PT model.
Results analysis and discussion: Fig. 11 shows the classification performance of PT and GT models. It is observed from the figure that CNN-GT/TDNN-GT achieves the highest Recall, Precision, and F1-Score, which range from 0.97 to 0.98. We can also see that most PT models have slightly lower yet similar classification performance as the GT models. For example, CNN-PT-1 has similar performance to TDNNGT (Recall: 0.93 vs 0.98; Precision: 0.96 vs 0.98; F1-Score 0.95 vs 0.98). The results indicate that a PT model, just built upon one speech sample of the target speaker, can still recognize most speech samples from the target speaker, and also reliably reject to label other speakers as the target speaker at the same time. The worst-performing model TDNN-PT-4 achieves a Recall of 0.82 and a Precision of 0.86, which is still acceptable to recognize the target speaker. Overall, we note that the PT models can achieve similar classification performance compared with the GT models. Based on the findings, we are motivated to use a PT model to approximate a GT model in generating AEs, and aim to further explore whether PT-AEs are effective to transfer to a black-box GT model.
C. Performance of Digital-line Speaker Recognition Models
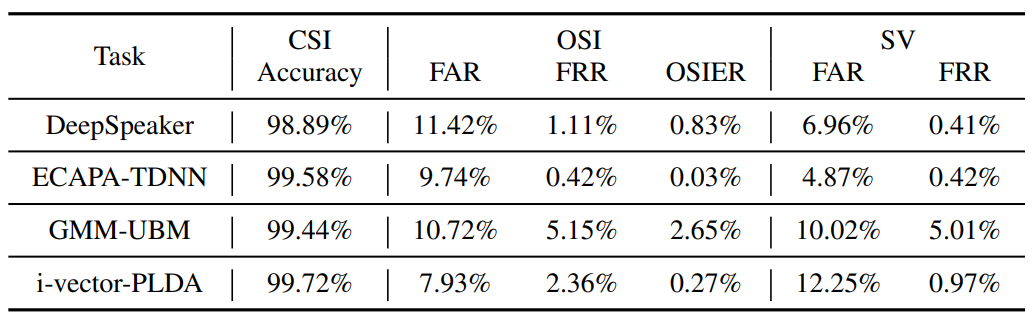
Table IX shows the performance of the target speaker recognition models, where accuracy indicates the percentage of speech samples that are correctly labeled by a model in the CSI task; False Acceptance Rate (FAR) is the percentage of speech samples that belong to unenrolled speakers but are accepted as enrolled speakers; False Rejection Rate (FRR) is the percentage of samples that belong to an enrolled speaker but are rejected; Open-set Identification Error Rate (OSIER) is the equal error rate of OSI-False-Acceptance and OSI-False-Rejection.
D. Robustness of PT-AEs over Distance
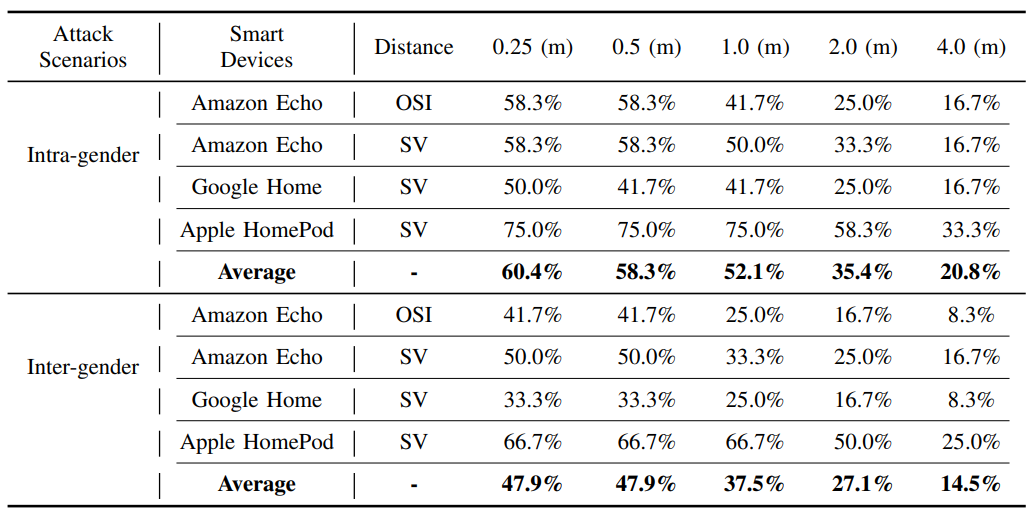
We aim to further evaluate the robustness of the PT-AE attack in the over-the-air scenario with different distances from the attacker to the target. We set different levels of distance between the attacker (i.e., the JBL Clip3 speaker) and a smart device from 0.25 to 4 meters. The results in Table X show that the ASR of the PT-AE attack changes over the distance. In particular, we can see that there is no significant degradation of ASR when the distance goes from 0.25 to 0.5 meters as the ASR slightly decreases from 60.4% to 58.3% in the intergender scenario. There is an evident degradation in ASR when the distance increases from 2.0 to 4.0 meters (e.g., 27.1% to 14.5% in the inter-gender scenario). This is due to the energy degradation of PT-AEs when they propagate over the air to the target device. Overall, PT-AEs are quite effective within 2.0 meters given the perturbation energy threshold of ϵ = 0.08 set for all experiments.
E. Discussion on Defense
Potential defense designs: To combat PT-AEs, there are two major defense directions available: (i) audio signal processing and (ii) adversarial training. Audio signal processing has been proposed to defend against AEs via down-sampling [74], [118], quantization [112], and low-pass filtering [72] to preserve the major frequency components of the original signal while filtering out other components to make AEs ineffective. These signal processing methods may be effective when dealing with the noise carrier [118], [72], [52], but are not readily used to filter out PT-AEs based on environment sounds, many of which have similar frequency ranges as human speech. Adversarial training [51], [78], [20], [25], [97], [102], [109] is one of the most popular methods to combat AEs. The key idea behind adversarial training is to repeatedly re-train a target model using the worst-case AEs to make the model more robust. One essential factor in adversarial training is the algorithm used to generate these AEs for training. For example, recent work [118] employed the PGD attack to generate AEs for adversarial training, and the model becomes robust to the noise-carrier-based AEs. One potential way for defense is to generate enough AEs that cover a diversity of carriers and varying auditory features for training. Significant designs and evaluations are needed to find optimal algorithms to generate and train AEs to fortify a target model.
This paper is available on arxiv under CC0 1.0 DEED license.