

Everyone wants to have stable access to the daily routine of apps at their fingertips, and the moment it fails to deliver for the smallest measurable time period, we all become frustrated over how SWE compensations are overrated. Imagine those engineers’ frustration at the same moment in case data lags due to a DoS attack occurring out of thin air and the server requests queue becomes overwhelmed with both legit users and malicious traffic.
Well, if such an event is thought to happen rarely the idea is way off: constant is the word much closer to truth. Apart from malicious decentralized attacks with specified targets, there are numerous sub-tasks requiring small-time flooding of packets to a company API. For instance, unauthorized access through identifiers brute-forcing, which is deeply explained in my other HackerNoon article:
Regardless of the initial purpose, a solution to such a versatile area of malicious requests occurring would be best achieved through traffic filtering techniques separating normal users from automated scripts. Captcha and the like focus on these precise distinguishable attributes attached to both groups to pass first and block second.
They are less efficient, however, with curing data flooding the servers; the problem in itself is only solved through better and faster filtering approaches. Those are described and compared in this article.
High-Level Languages
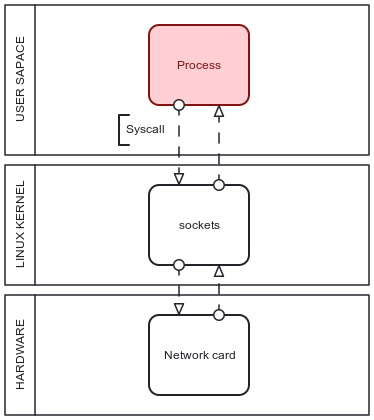
The most straightforward method to analyze and filter incoming traffic is to access it as soon as it leaves kernel space and enters user space. It brings simplicity in setting rules and handling parallel processing as many high-level programming languages provide useful solutions to such tasks in the form of libraries such as Django or Flask in Python.
It operates with classes responsible for data packet interpretation at the user space level or entire requests with all the headers, metadata, and payload fields. The benefits of this interaction level consist of speed to build logic for filtering or passing incoming data with the option to handle entire requests as a combination of packets rather than their sequence separately.
However, the development process usefulness, in general communicating with traffic at a high-level programming language level means it takes the data a lot of steps and layers to pass between to get to the given point, which in itself lacks efficiency in speed and computing power use as presented in Figure 1 as any received data packet travels through the system bottom-up. The earlier the packet is analyzed, the more efficient the backend system in total becomes.
BPF Observability Monitoring
There is a further approach to filtering incoming traffic based on it meeting set requirements or leaving the approved boundaries. The logic for filtering can be applied to features like the sender IPv4 address of a packet or a higher-level specific header field attached to an HTTP request. Software solutions allow you to significantly customize the given logic of passing any structure through or shunting it from the system altogether.
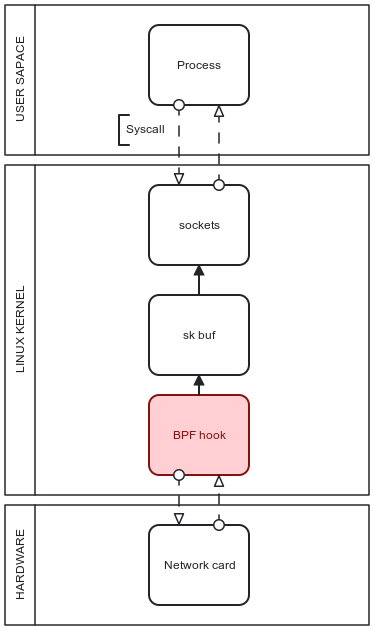
There are different levels at which collected traffic data can be accessed, and a useful tool for its monitoring uses BPF as a network tap monitoring events on a local network. Basic events to be monitored with the approach are system calls, function entries/exits, kernel tracepoints, network events, and others.
The main benefits of BPF include an ability to attach co-called hooks to a predefined point in system layers and execute convenient llvm-compatible code written by the user without rewriting kernel methods themselves but rather by setting access to observe their workflow and interfere in specific use cases.
BPF hooks can be set to monitor incoming traffic in various abstraction levels. Once a packet reaches the kernel right after logging the fact, it initiatessk_buff metadata structure that represents the reference to the given packet in the system. It is the first encounter on the kernel level that has the ability to be monitored and handled in terms of unpacking its headers and evaluating whether any of them mismatch with pass policies and have to be dropped from further pipelines.
BPF hook can be set at this point, however, the case lacks efficiency because resources have already been allocated to transfer packet-related data through to the kernel and initiate packet structure there. With a high load of incoming packets, such a logic forces the CPU to spend extra resources for processing unnecessary data, and to scale the approach it has to target filtering traffic as early in the pipeline as possible to preferably alleviate kernel load in total.
The deepest level of monitoring takes place before a packet is sent up the network stack and is called XDP. The logic is executed in the network interface controller driver after the interrupt processing takes place calling for packet handling to be moved up the queue in CPU workflow and drop current tasks if applicable.
Thus, it is safe to assume that packets can be analyzed before any memory allocation is needed by the network stack itself as it can be an expensive operation regarding time and computation power. It makes the XDP approach stand out as one of the most efficient approaches due to filter execution taking place with minimum processing beforehand, and therefore minimum resources spent on packets bound to be dropped. The top-down structure of a packet path through the system and optimal BPF hook location are present in Figure 2.
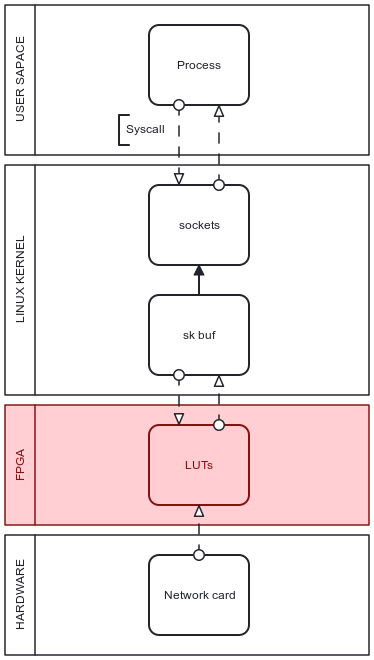
As the goal to eliminate as much kernel load as possible continues there is a need for further technologies applicable to traffic filtering beyond BPF software monitoring realization. The hypothesis is to introduce an entirely separate link between the hardware network card and kernel space blocks from Figure 2 behaving in a similar way to BPF hooks but using no rather than little CPU resources.
This architecture is then optimized to scale traffic load processing as the kernel is excluded from the filtering logic and only handles packets that do not match any criteria to be dropped.
FPGA-Based Solutions
Practical architecture for traffic analysis with software and hardware combination appears from introducing the FPGA integrated circuit component between the network card and the CPU in a packet path through the system. It is specifically designed to be "field configurable" to adapt use-case scenarios to any needed architectural use. In the case of traffic filtering, FPGA is able to decode packet headers such as IP-header, TCP-header, or Ethernet-header as well as packet payload itself.
The initial approach focuses on matching IP headers with any ruleset that defines if it should be dropped because the parsed IP is in any case needed further in traffic routing regardless of monitoring logic existence. Parsing IP headers at this stage follows the goal of minimizing CPU resources and also even manages to take some decoding load from it as well. The updated system architecture for traffic filtering is presented in Figure 3.
FPGA filtering methodology is built on substring patterns matching with the help of DFA deterministic finite automatons followed by the Knuth–Morris–Pratt algorithm (KMP) for pattern searching. The patterns are taken from up-to-date data sources of the most commonly used malicious code signatures, and the number of those in active matching operation is only limited by the board logic units as 4-5 units are usually allocated for a single pattern comparison.
There are lots of general architectures for concurrent matching, the most efficient though being the one with parallel modules comparing different signatures and providing a final decision state with either of two ways:
-
Choosing a pattern that matched the most out of the existing ones based on giving every signature a weighting value or probability of match after the comparison. In this case, a combination of all patterns should be determined as a ruleset for traffic pass requirements, and all the other packets failing to match signatures are then dropped.
-
Reversed approach of transporting packets further in case they matched none of the signature comparison modules. This logic focuses on matching explicitly defined malicious signatures in packet ip or payload to drop based on any of the selected "blocking" parts.
Data from TCP/IP protocol is set to arrive in 32-bit fragments afterwards the decoding process with each such block consisting of beginning and ending headers payload. They are passed to a pattern matching module with two parallel memory buffers storing matching patterns and command signals.
The handling process includes reading from these buffers with the use of a pointer to address memory while the data scanning module initialises a number of DFAs to search for matches inside each block. Each automaton supports 1-bit matching signal and when the pointer reaches the end of packet data either of two states is selected:
-
Packet-related pointer is set to the exit queue if matching signals from all the DFAs determine match/miss with a logic module responsible for informational purpose but not for the traffic filtering.
-
In the case when one or more signals point out that specific matches are found defined to drop packets. then the pointer addressing exit queue is not set for the given packet, and it is thus not passed further the path and shunted.
The described logic is basic and provides additional space for optimizations. For instance, extra rules can be set to immediately drop non-ip packets from the flow as they are definitely not supposed to pass to CPU or give priority to TCP/IP packets above all the rest if such requirements are needed.
There is also an important part of keeping the matching modules signatures updated to handle any malicious traffic efficiently. Content for network packet filtering should be based on existing software systems for protection against frequently observed attack types. One of the widely used open-source systems is Snort.
It is an IDS with a constantly evolving architecture and an extensive set of rules for detecting unwanted network traffic, and because of such an agile approach to problem solution and outsourcing updates process for signature can be chosen as the basic software solution, by converting Snort rules and patterns into any HDL language, it is possible to offer a complete hardware and software combination solution based on it, obtaining a design that includes a packet filter based on a hardware implementation of Snort rules, as well as a module for extracting and rewriting IP packet header fields.
The given architecture provides an up-to-date set of filtering for common attacks and, less harmful but still flooding, regular parsing for modelling metrics in competitors’ analysis described in detail in my other entry:
https://hackernoon.com/data-analysis-applied-to-auto-increment-api-fields?embedable=true
The disadvantage of using Snort methods directly is its single-threaded processing. The architecture may not be able to detect intrusions in real time, especially in high traffic networks. A further development of the approach using the Snort library is a two-layer structure, where Snort will act as a second line of defence and will only be executed when packet body analysis is needed.
To increase efficiency, dynamic sending of the most frequently used rules and signatures to the FPGA can be introduced. The module would then act as a first line of defence that speeds up detection by filtering all traffic looking for attack patterns based on Snort rules and signatures, and would send flagged suspicious traffic to the second stage of inspection.
This will also give a higher margin of error on false positive scenarios, as the second line filtering will be able to send the packet back if there is no confirmation of any malicious content in the payload.
The considered methods of filtering will also be suitable for solving vulnerabilities from attacks like TCP Sequence Prediction Attack, in which an attacker can interfere with a TCP connection by picking up the current range of Sequence number in the packet header, while simultaneously launching a DoS attack on the authentic sender in order to be the first to transmit data and thus hijack the tunnel connection.
There is an approach through encryption on the sender side and decryption of packets on the FPGA side of the module, which will not additionally load the processor but will solve the given issue. Such a system includes modules that perform data column shuffling and set partitioning into smaller subsets (and corresponding inverse operations) and on-the-fly key signing without delaying storage access.
An alternative already integrated in the considered solutions would be to filter local ip from external senders using an appropriate in-memory buffer checking pattern that solves the same problem without consuming CPU resources.
One of the most splendid approaches is to implement a hybrid system of hardware and software interaction by implementing primary packet filtering on a programmable module with metadata sent to further analysis with software. The same interaction in reverse can then send results of software analysis back to FPGA modules for almost real-time changes in the patterns checking packets.
Due to such data exchange, the filtering ruleset cluster can automatically adapt by constantly updating, for example, the set of malicious IP addresses of the sender during the ongoing DoS flow attack directly. It allows to consistently shift the task load from software to FPGA modules thus continuously reducing the overall system load.
The presented system also highlights an additional approach to quickly verify a high number of IP addresses through collecting hop table distributions after binary search over LUTs and compressing ip ranges to a uniform structure within them.
Applications Comparison
The theoretical overview of traffic filtering architectures includes a number of solutions with the use of software and software-hardware integration approaches to access incoming packets in different path stages inside the system. Comparison in efficiency of all the described approaches is presented in Table 1 (Comparison of traffic filtering approaches).
|
Architecture solution |
Advantages |
Disadvantages |
|---|---|---|
|
High-level programming language script |
Development convenience, debugging simplicity |
Lack of efficiency in computing power use due to data passing numerous layers to get to class object |
|
BPF hook to kernel |
BPF attaches to observation point and does not require system rework |
BPF introduces numerous engineering concepts to set up the working system |
|
BPF hook to network card output |
The most efficient resources use in kernel space as data is analyzed the moment it leaves physical network card |
Takes understanding and access to deeper XDP levels in network protocols |
|
FPGA with parallel DFAs pattern matching |
Distributes traffic handling computing power load to specialized hardware from the CPU |
Lack of pre-built rulesets for ip-based patterns to filter |
|
FPGA with open-source signatures update |
Outsourcing up-to-date library for malware signatures to |
Dependency on third-party software and customisation limits |
|
FPGA with TCP Sequence Prediction Attack prevention |
Includes security layer for preventing attacks beyond focusing on filtering traffic |
LUTs for Sequence Prediction Attack prevention diminish production output for parallel patterns matching |
Conclusion
Described methods comprise top-level overview of technical traffic filtering approaches used in various research and production setups. They do not exist in isolation but are rather combined with sophisticated and always evolving algorithms detecting which ip-addresses are blacklisted which are the topic for an entirely separate article.
Diving into hardware details is necessary to evaluate and appreciate combined efforts between engineers and developers (also system architectures, cybersecurity experts, all their managers - you got the point) to get that 15-second cat video right back to you seamlessly one after another though the hell of DoS-level request floodings happening in dozens all over the place.