
Authors:
(1) Xiaohan Ding, Department of Computer Science, Virginia Tech, (e-mail: xiaohan@vt.edu);
(2) Mike Horning, Department of Communication, Virginia Tech, (e-mail: mhorning@vt.edu);
(3) Eugenia H. Rho, Department of Computer Science, Virginia Tech, (e-mail: eugenia@vt.edu ).
Table of Links
Study 1: Evolution of Semantic Polarity in Broadcast Media Language (2010-2020)
Study 2: Words that Characterize Semantic Polarity between Fox News & CNN in 2020
Discussion and Ethics Statement
Study 2: Words that Characterize Semantic Polarity between Fox News & CNN in 2020
Method and Analysis
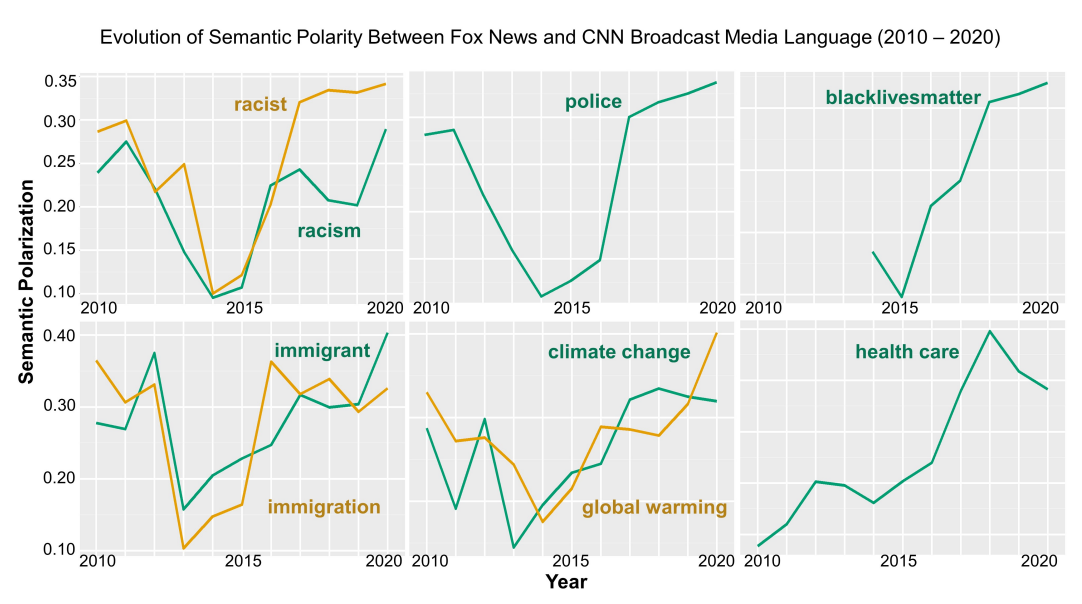
Semantic polarity between Fox and CNN is predominantly high in 2020, echoing the series of highly publicized events in the media (e.g., COVID-19, George Floyd, and BLM demonstrations) that reified a widening ideological gap among the American public on a number of issues. Hence, in Study 2, we aim to go beyond providing a mere quantification of polarization by examining how the language surrounding the use of contentious keywords by CNN and Fox contributes to the 2020 peak in semantic polarity. In other words, how does CNN and Fox News contextually differ in their use of topical keywords on their news programs in 2020? To answer this question, we identified attributive words or contextual tokens that are most predictive of whether a speaker turn containing a topical keyword was from CNN or Fox in 2020. This task entailed a two-step process. First, we trained a BERT-based classifier using the 2020 corpus of closed captions from both stations to predict whether a speaker turn was from CNN or Fox. Then, we used a model interpretation technique called Integrated Gradients (Sundararajan, Taly, and Yan 2017) to identify which words (except for the topical keyword) in each speaker turn contributed most to the classification decision.
Classifying 2020 Speaker Turns. To identify whether a speaker turn was broadcast from Fox or CNN in 2020, we built six BERT-based classifiers pertaining to each topic. First, we merged the 2020 corpus of speaker turns, each containing one of the nine topical keywords by topic (e.g., speaker turns containing “racism” or “racist” were merged into one topical corpus).
For each of the six topical corpora, we trained BERT (BERT-Base-Uncased) by masking 15% of the words in each speaker turn and trained the model to fill in the masked words using a standard cross-entropy loss function. We then fine-tuned the adapted model to predict whether a speaker turn was from CNN or Fox News. For this step, we split the data into 80% training, 10% validation, and 10% test sets. We set batch sizes to 16, training epochs to 6 with 3-fold cross-validation, and used AdamW for optimization with a learning rate of 2e−05. We used PyTorch for all model implementations.
Model Interpretation. To identify the contextual language or the attributive words that contributed most to the 2020 semantic polarity between CNN and Fox News, we used Integrated Gradients (IG) to interpret the classification results from our BERT-classifier in the previous step. IG is an attribution method that allows us to understand how much an input feature contributes to the output result of a deep neural network (Sundararajan, Taly, and Yan 2017). This post-hoc interpretability technique combines the input’s gradients by interpolating in short increments along a straight line between a baseline x (usually a vector with all zeros) and the input x 0 . Formally, if F : Rn → [0, 1] represents BERT, then the integrated gradient (IG) of the i th dimension of x is:
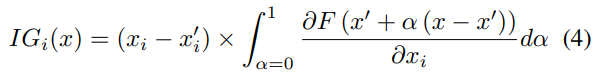
Large pre-trained transformer-based language models, such as BERT may have strong predictive powers, but their multiple nonlinearities prevent users from directly attributing model outputs to various input features. To overcome this lack of interpretive insight, we leverage IG to identify words that are most attributable to each predicted class. Thus, we identify which contextual words within a speaker turn (input features of a classifier) contribute most to, or are most predictive of the output decision, namely, whether the speaker turn is from CNN or Fox News in 2020.
Results
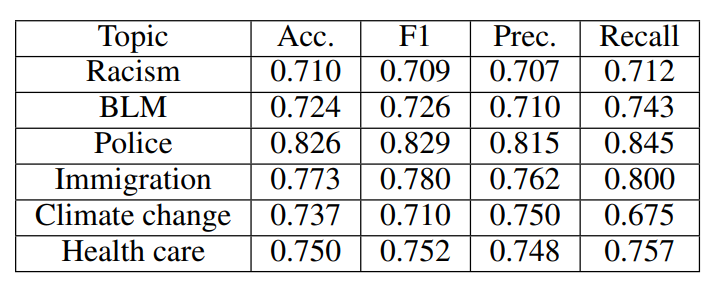
Our BERT-classifier distinguishes 2020 speaker turns from CNN and Fox News with a mean accuracy of 75.3% across all six topics (Table 3). Model performance is highest for speaker turns topically focused on the police, corresponding to Study 1 findings demonstrating highest SP scores for “police” across all keywords in 2020.
In Table 4, we show the top 10 words most predictive of how CNN and Fox News discuss the six topics on their news programs in 2020. To avoid noise caused by low-frequency words, we limited our token selection to words with a frequency above the 95th percentile. We categorized the tokens with the highest and lowest attribution scores ranging from positive (attributed to CNN) to negative (attributed to Fox News) values for each topic. As shown, across all topics, none of the top tokens overlap between the two stations, indicating the drastically distinct contexts in which the two channels discuss key topics in 2020. For example, words like “illegal”, “enforcement”, and “order” contextualize immigration discussions in a rather legalistic manner on Fox News whereas, “parents”, “family”, “children”, “daughter”, and “communities” - humanizing words connotative of family relations best predict how CNN discusses the same topic. Both stations may be discussing the same topic with identical keywords, but the contextual language surrounding their discussion is strikingly different. Such divergence sheds light on the underlying differences in the linguistic signature of televised media language that help explain the 2020 peak in semantic polarity between the two stations.
This paper is available on arxiv under CC 4.0 license.